CSC2626 Imitation Learning for Robotics
Week 11: Learning from Videos
SMPL (Skinned Multi-Person Linear Model)

Hand motion estimation in AR/VR headsets

Frame-by-frame human pose detectors
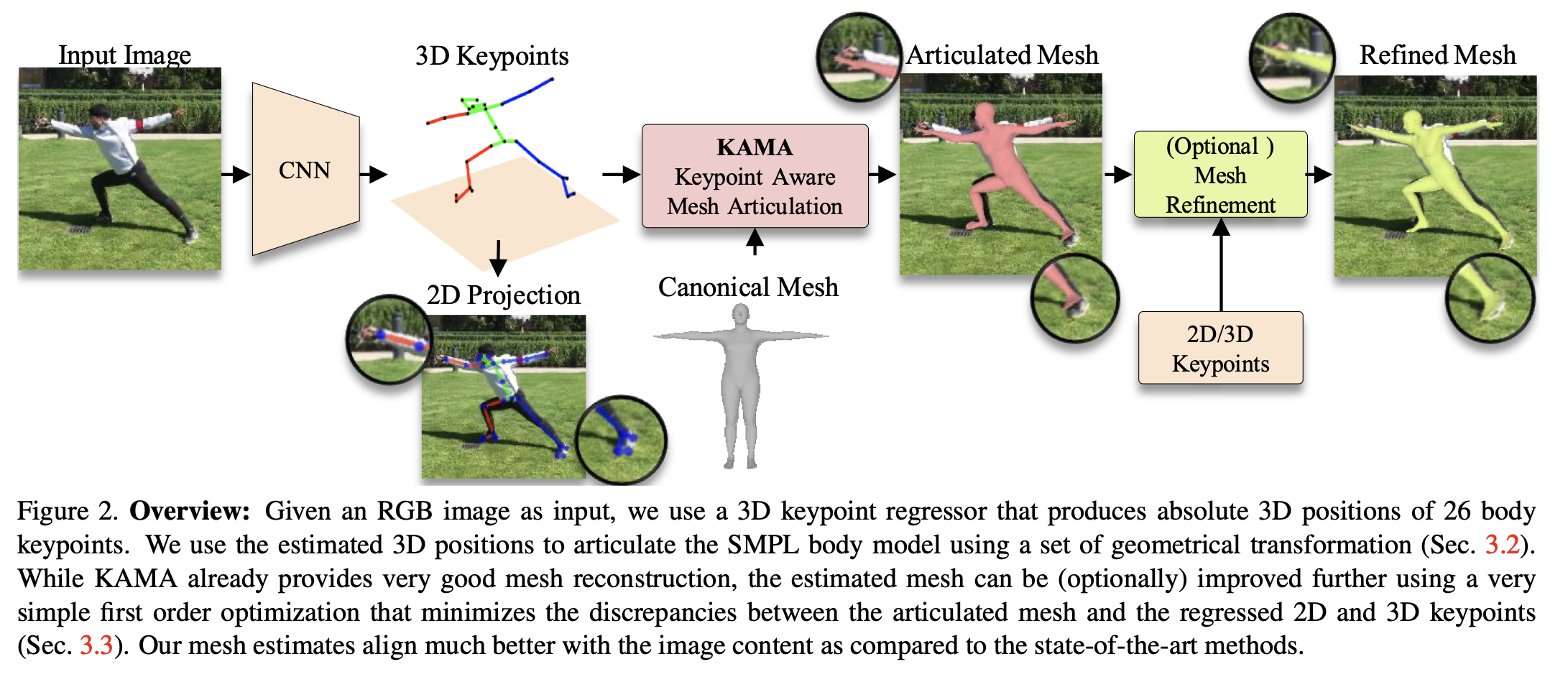
KAMA: 3D Keypoint Aware Body Mesh Articulation. Iqbal, Xie et al. 3DV 2021. https://arxiv.org/abs/2104.13502
Motivation
Frame-by-frame human pose estimators exist but are not good enough. We can correct them with physics.

\(\Rightarrow\)

![]()
System overview
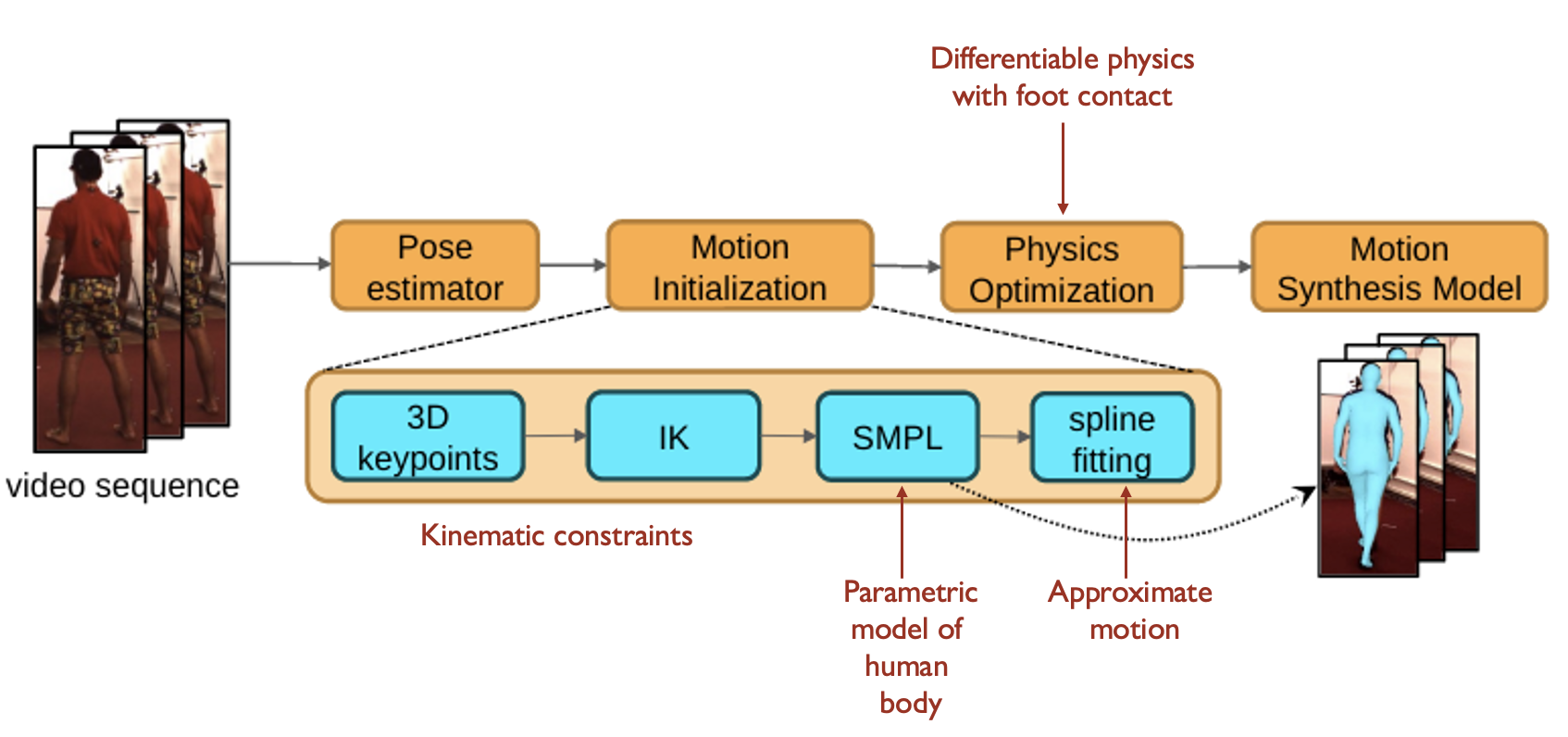
Physics-based Human Motion Estimation and Synthesis from Videos.
Xie, Wang, Iqbal, Guo, Fidler, Shkurti. ICCV ’21.

Kevin Xie




Motion retargeting: formulating a loss function
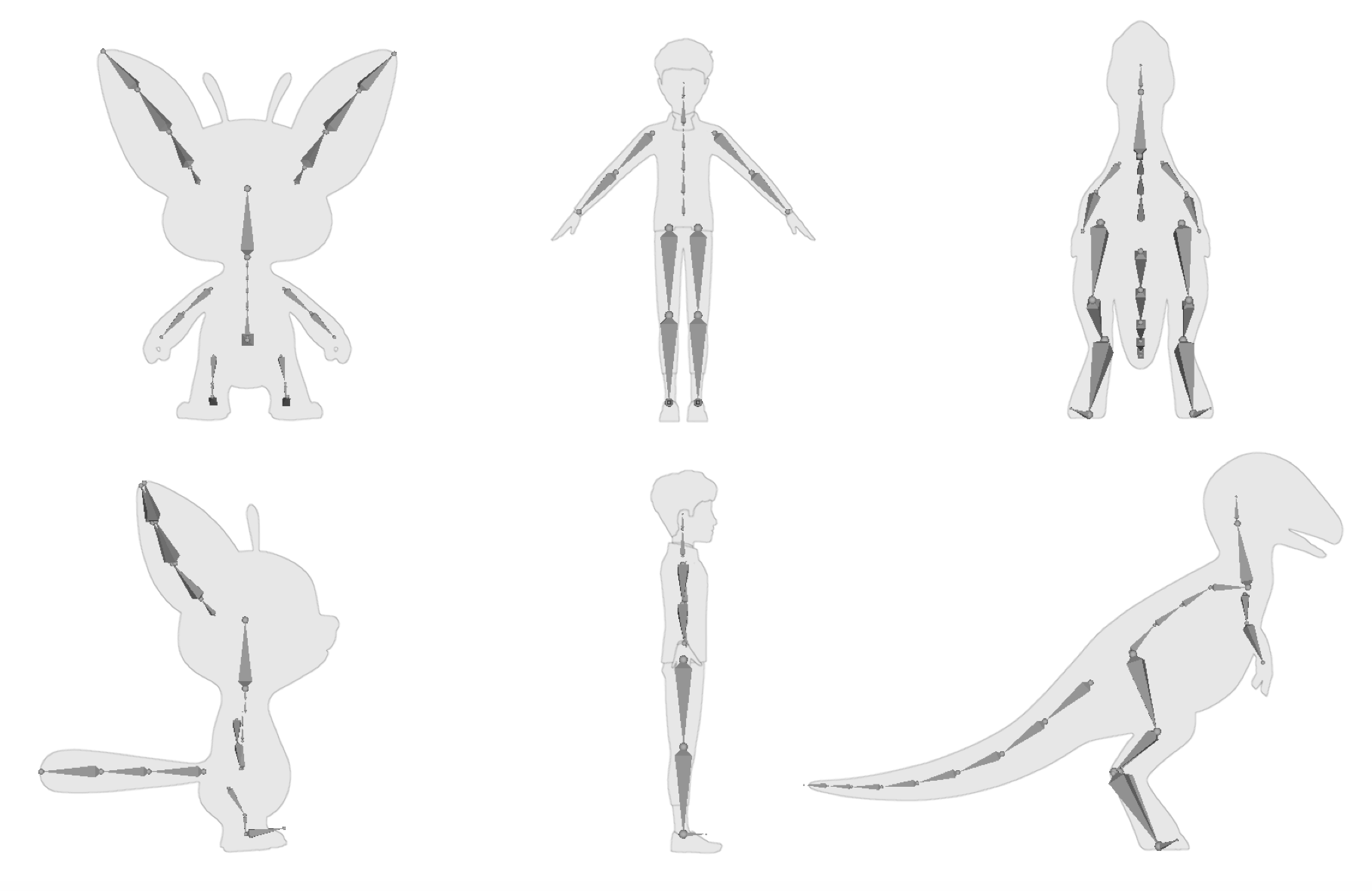
Motion retargeting loss function:
- Tracking error
- Respecting joint limits
- Avoiding self-collisions
- Respecting dynamics
- Smooth motion
Issue: source and target system have different dimensionality!
Potential fix: need to decide joint mappings from source to target
Motion retargeting from human to robot hands




Motion retargeting loss terms:
- Tracking error
- Respecting target joint limits
- Avoiding self-collisions in target
- Respecting target dynamics
- Smooth motion for target
Issue: source and target system have different dimensionality!
Potential fix: need to decide joint mappings from source to target
Large video reconstruction models
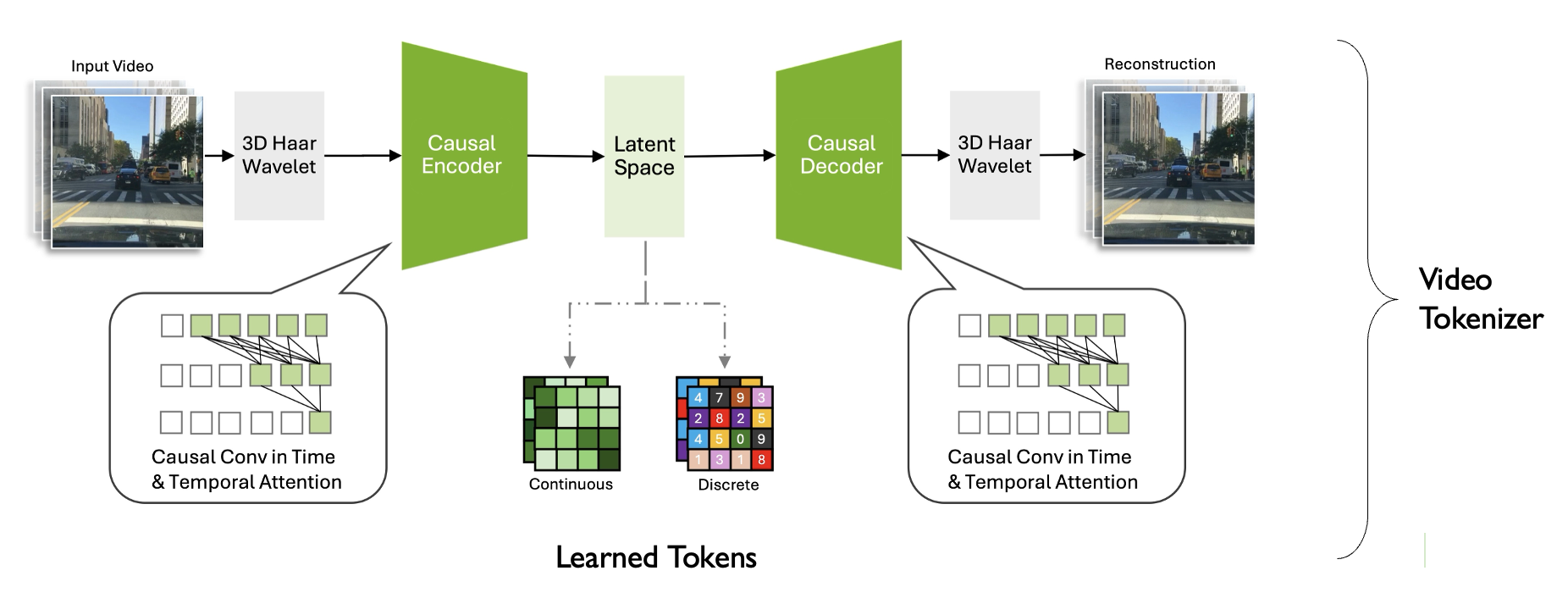
If you learn a good token representation for videos, then you can learn a latent dynamics model over it.
Cosmos model from NVIDIA. https://research.nvidia.com/labs/dir/cosmos-tokenizer/
How can we use video models in robotics?

Video prediction models as rewards for RL. Escontrela et al. NeurIPS 2023.
Another idea: dynamics models with learned action spaces
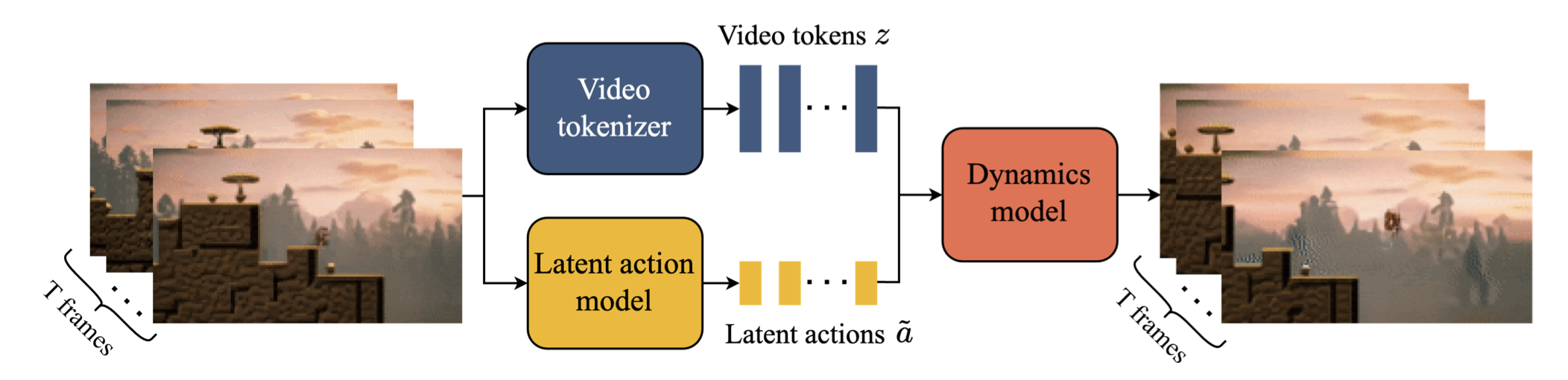
Need to manually map robot actions to latent actions

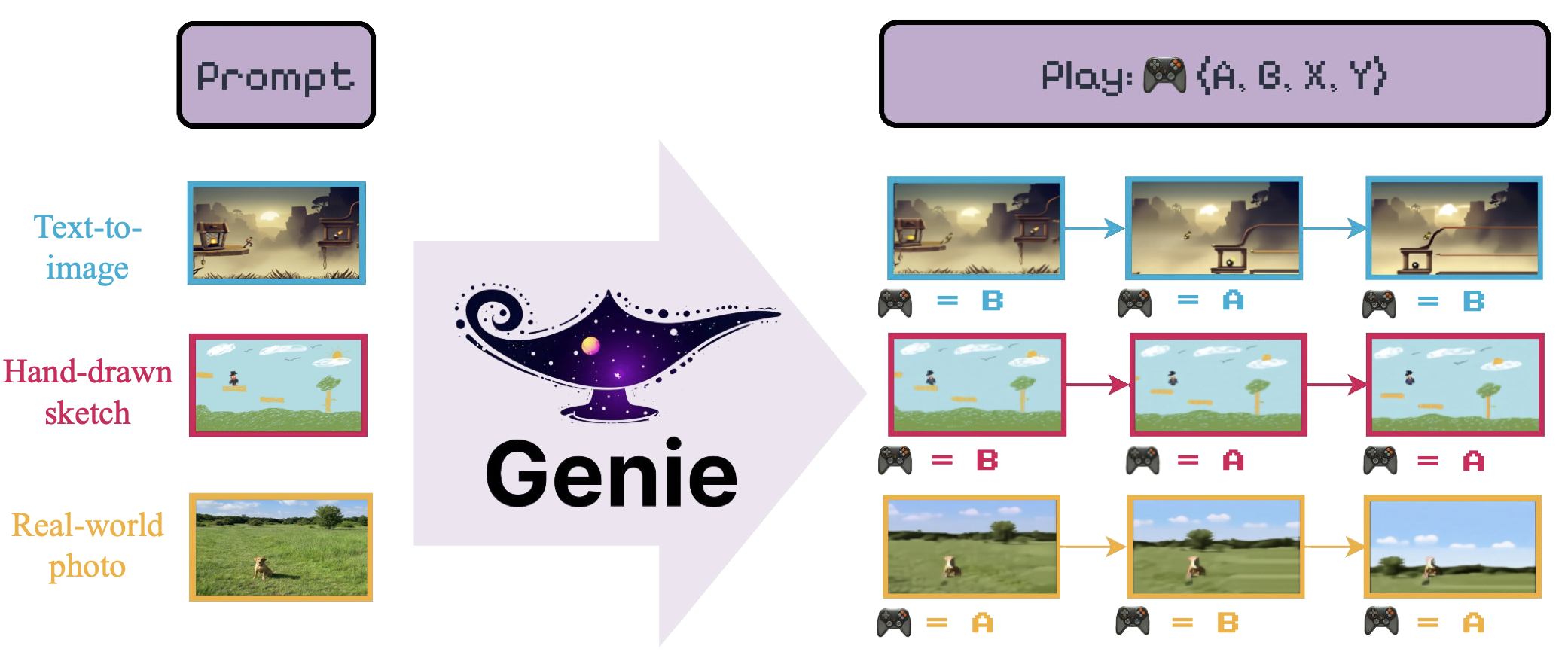
Genie