Main Hypothesis
Shared autonomy can improve human performance without any assumptions about:
dynamics,
the human’s policy,
the nature of the goal.
Week 10: Shared Autonomy and Human-in-the-Loop Learning
Siddharth Reddy, Anca Dragan, Sergey Levine UC Berkeley
Presented by Ioan Andrei Bârsan on February 22, 2019
iab@cs.toronto.edu

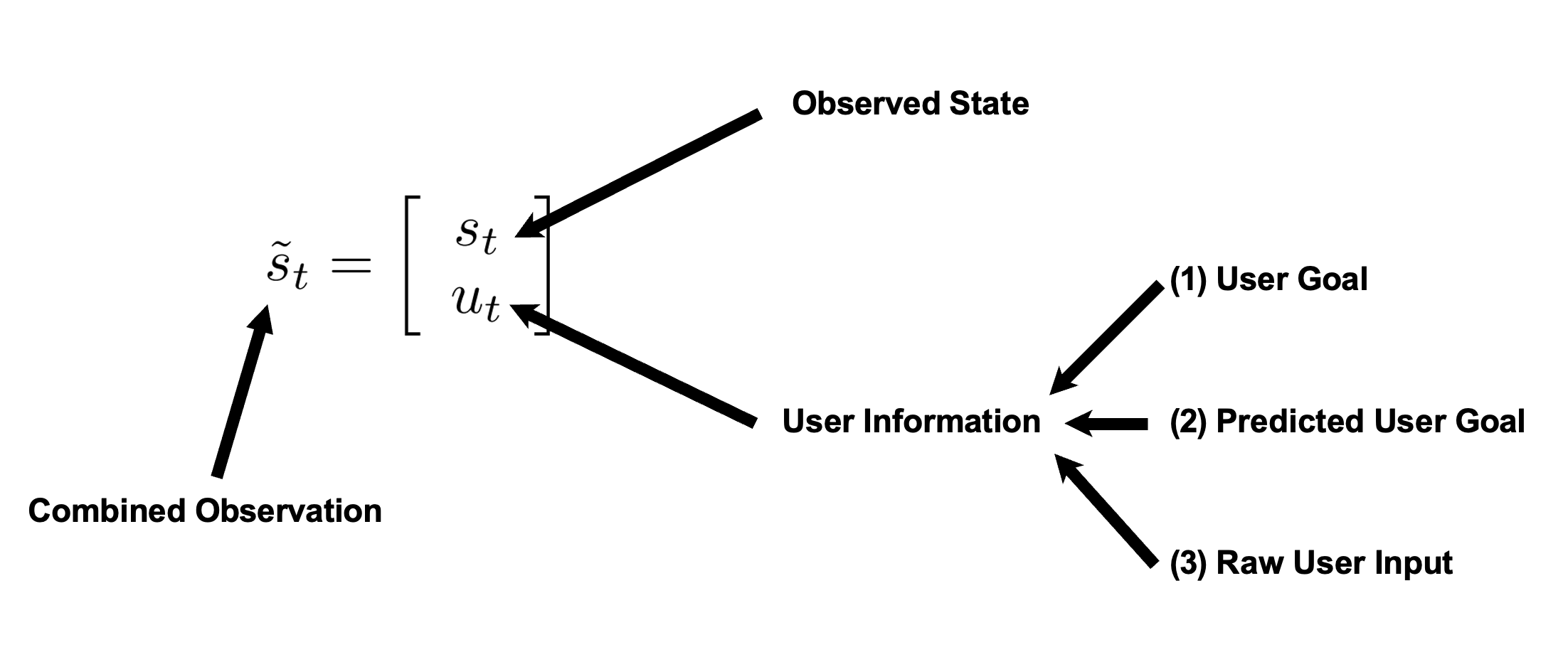
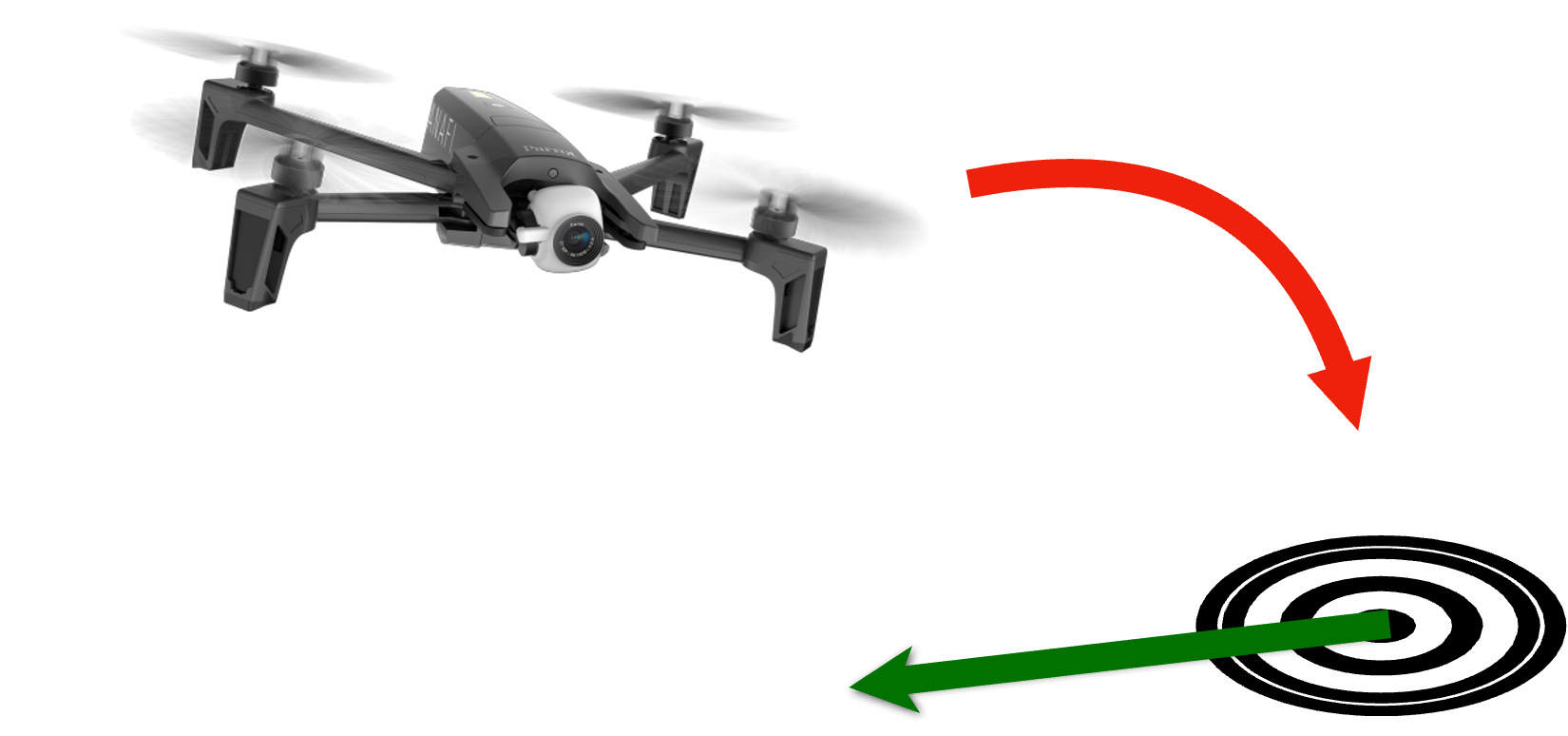
How can a robot collaborating with a human infer the human’s goals with as few assumptions as possible?
• Hard: Actuating a robot with many DoF and/or unfamiliar dynamics.
• Hard: Specifying a goal formally (e.g., coordinates).
• Easy: Demonstrating the goal indirectly.
• …let the machine figure out what I want!

Image source: “Multihierarchical Interactive Task Planning. Application to Mobile Robotics” Galindo et al., 2008

https://www.foddy.net/Athletics.html or Google “qwop”
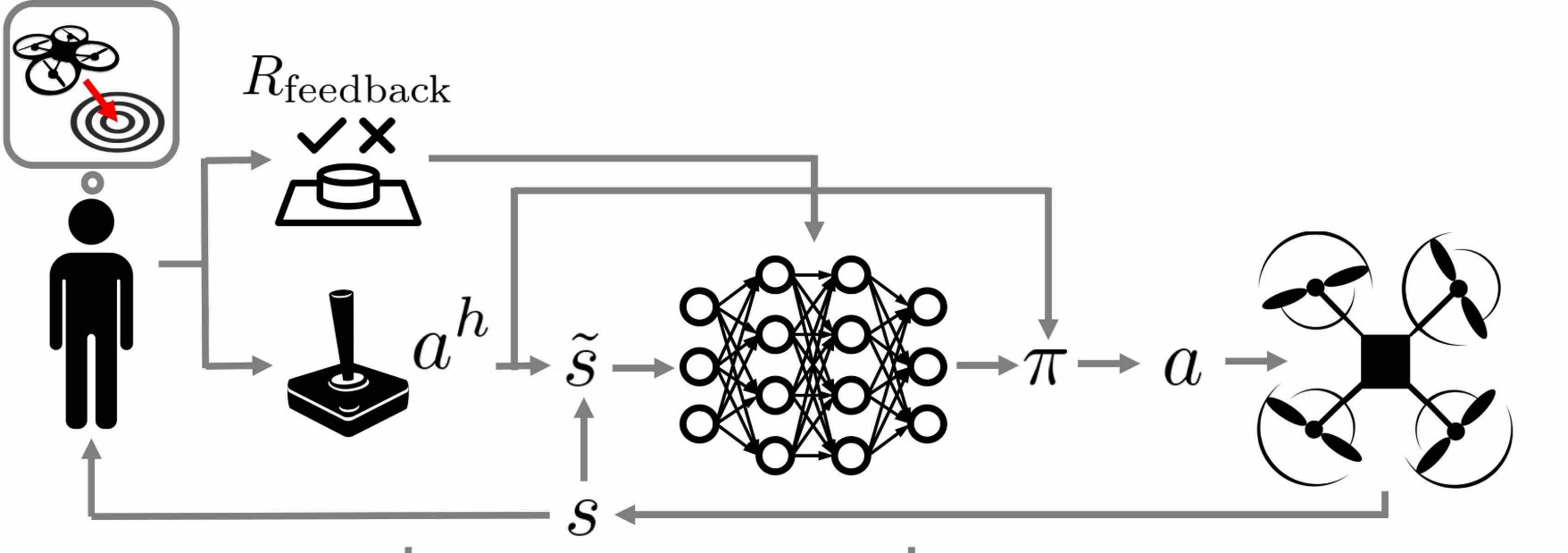
\[ \underbrace{R_{\text{feedback}}(s, a, s')}_{\text{unknown, but observed}} \]
Needs
virtual
“user”!
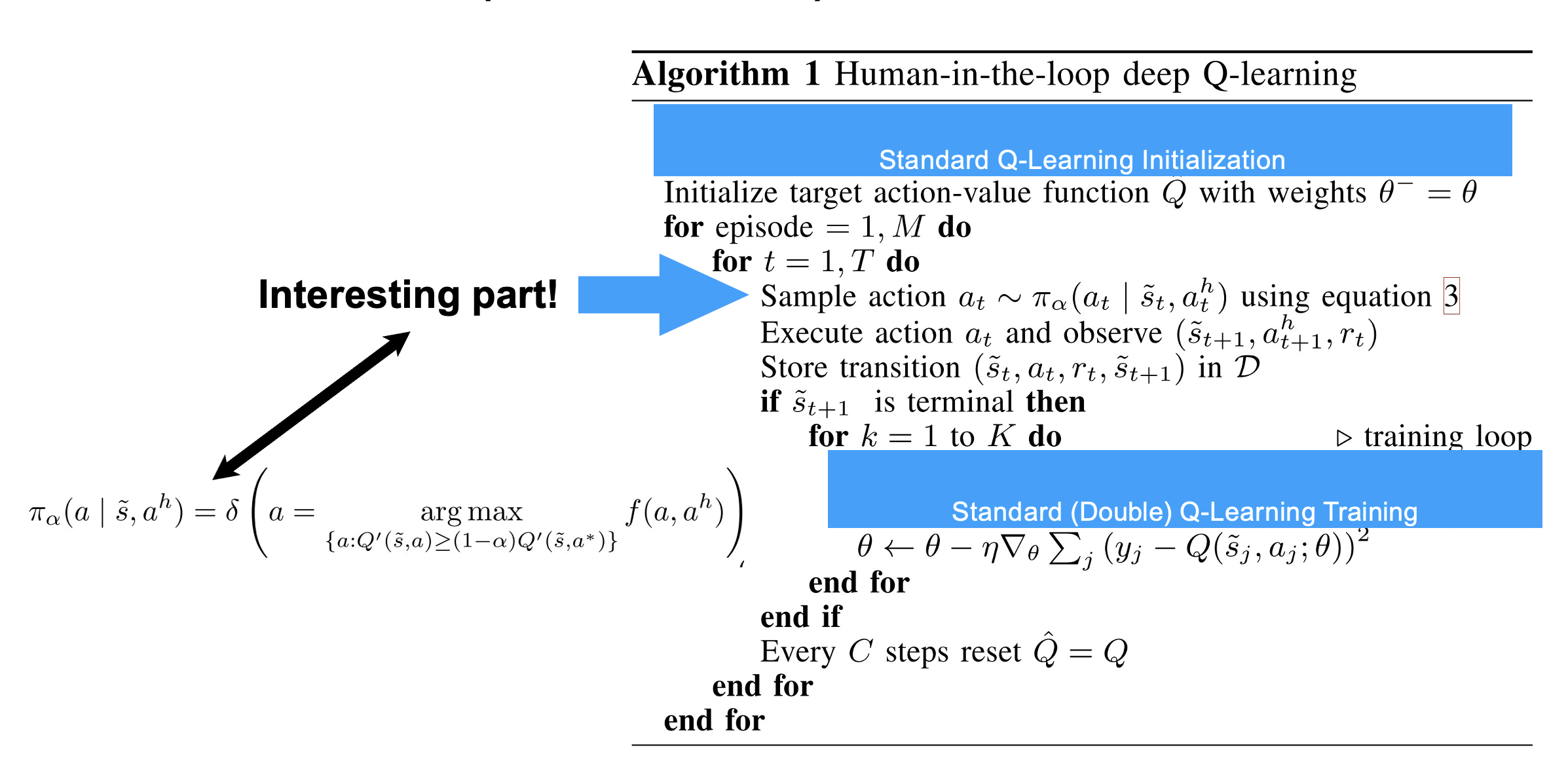
• The authors introduce three variants of their method:
Known goal space, known user policy.
Known goal space, unknown user policy.
Unknown goal space, unknown user policy.
Goal: Land drone on pad facing a certain way.
Pilot: Human, knows target orientation.
Copilot: Our Agent, knows where pad is, but not target orientation.
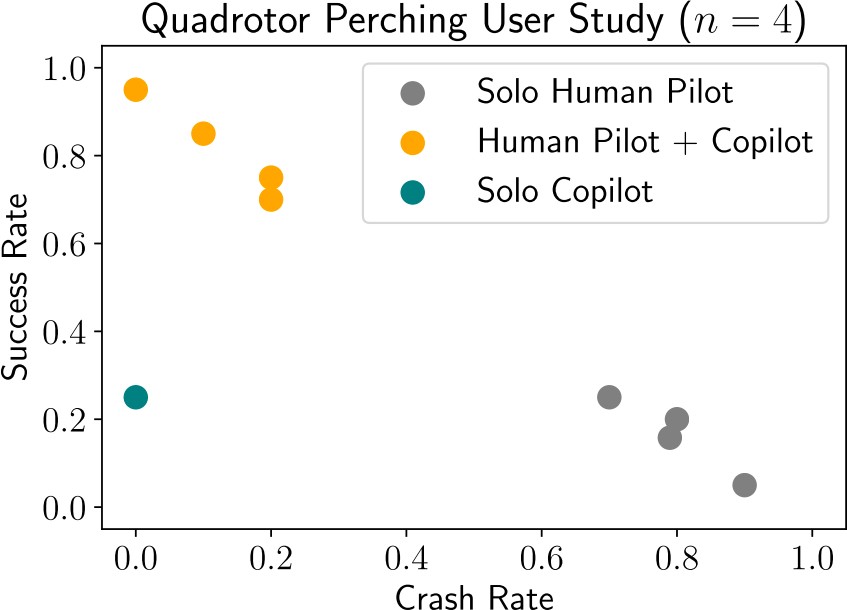
Important observation: Only n = 4 humans in drone study.
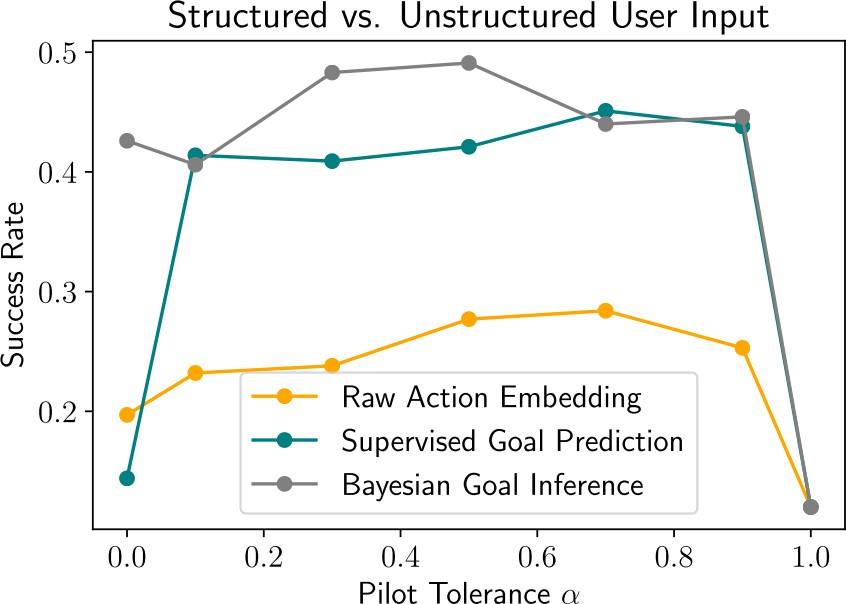
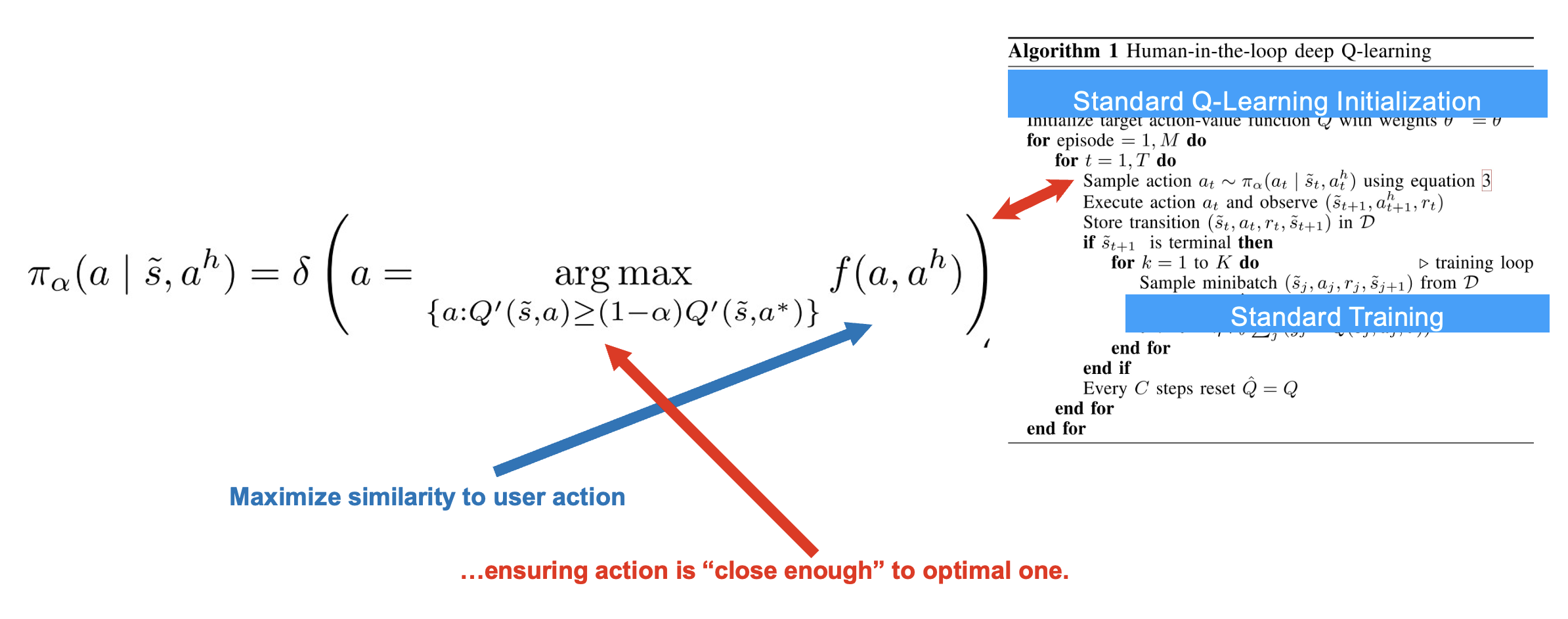
Higher alpha means we take any action. α = 1.0 means we ignore the pilot.
Experimented in virtual environment.
Q&A, if time permits it.
Project website: https://sites.google.com/view/deep-assist
Video of computer-assisted human piloting the lander.

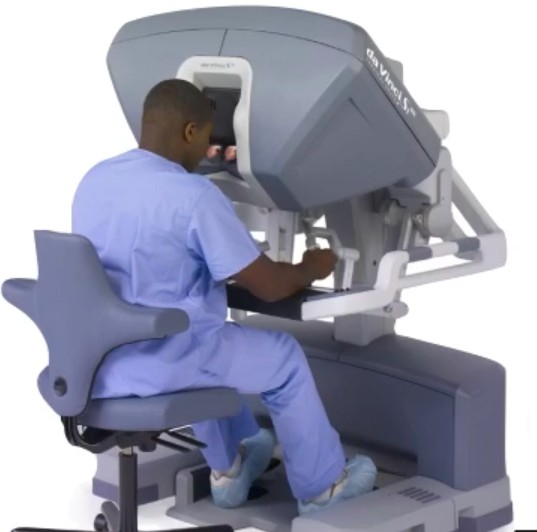



Noisy, insufficient degrees of freedom, tedious
Image credit: Javdani RSS2015 talk
 User Input
User Input
+
 Autonomous Assistance
Autonomous Assistance
=
 Achieve Goal
Achieve Goal
User Input
+
 Autonomous Assistance
Autonomous Assistance
=
Achieve Goal
Predict goal Assist for single goal
[Dragan and Srinivasa 13]
[Kofman et al. 05]
[Kragic et al. 05]
[Yu et al. 05]
[McMullen et al. 14]
…
+
Autonomous Assistance
=
 Achieve Goal
Achieve Goal
Predict goal Assist for single goal
[Dragan and Srinivasa 13]
[Kofman et al. 05]
[Kragic et al. 05]
[Yu et al. 05]
[McMullen et al. 14]
…
Predict goal distribution Assist for distribution
[Hauser 13]
This work!
+
Autonomous Assistance
=
![]() Achieve Goal
Achieve Goal
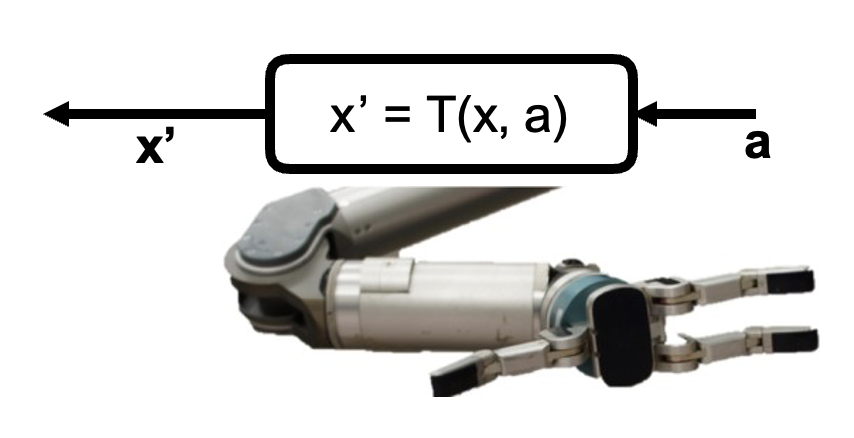
System dynamics: \(x' = T(x, a)\)
User (MDP) as \((X, U, T, C_g^{\text{usr}})\)
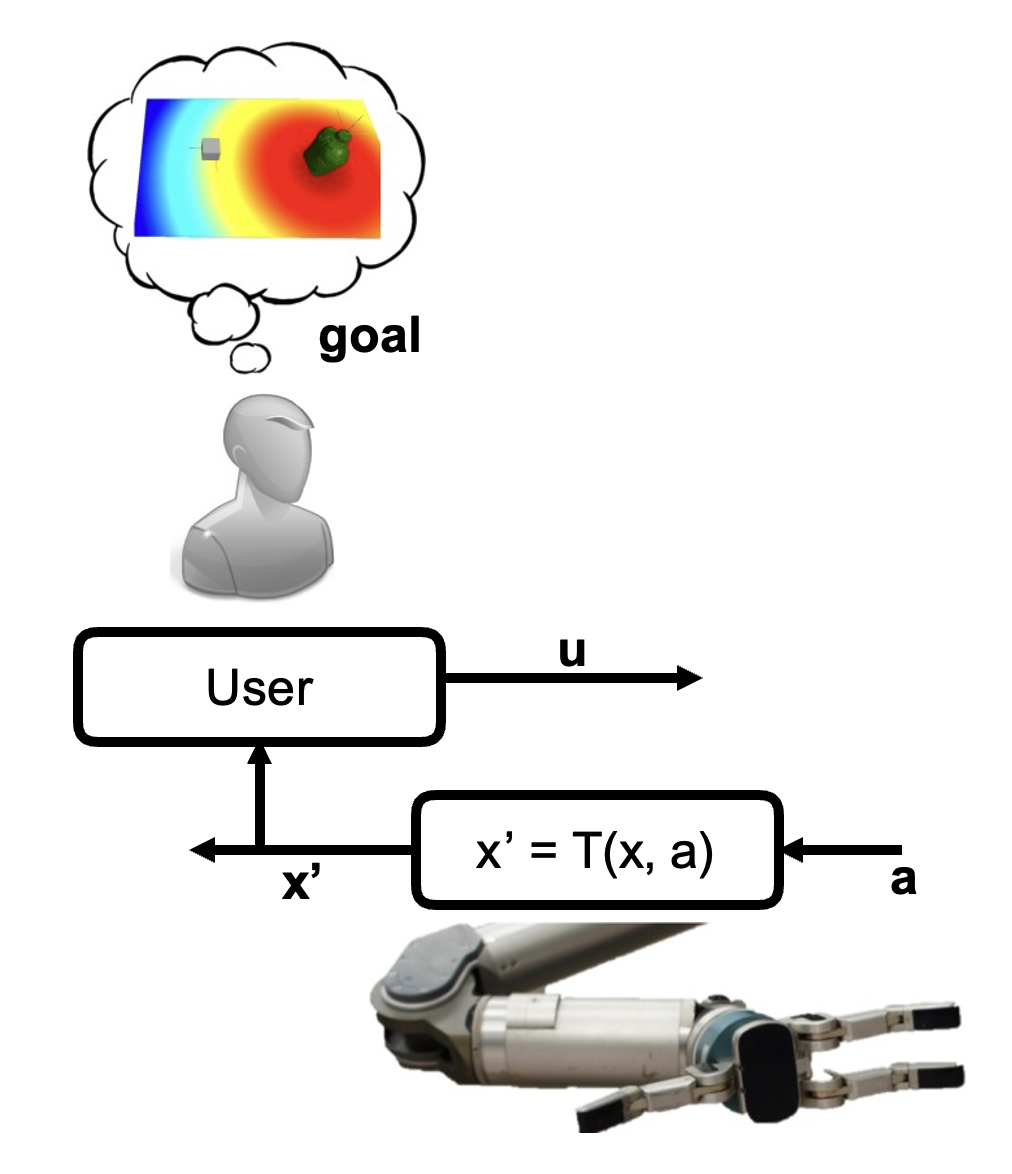
System dynamics: \(x' = T(x, a)\)
User (MDP) as \((X, U, T, C_g^{\text{usr}})\)
System (POMDP) as \((S, A, T, C^{\text{rob}}, U, \Omega)\)
\(p(g|\xi^{0 \to t}) = \frac{p(\xi^{0 \to t}|g)p(g)}{\sum_{g'} p(\xi^{0 \to t}|g')p(g')}\)
MDP solution:
\[V^{\pi^r}(s) = \mathbb{E}\left[\sum_t C^r(s_t, u_t, a_t) \mid s_0 = s\right]\]
\[V^*(s) = \min_{\pi^r} V^{\pi^r}(s)\]
POMDP solution:
\[V^{\pi^r}(b) = \mathbb{E}\left[\sum_t C^r(s_t, u_t, a_t) \mid b_0 = b\right]\]
\[V^*(b) = \min_{\pi^r} V^{\pi^r}(b)\]
HOP approximation:
\[V^{\text{HS}}(b) = \mathbb{E}_b\left[\min_{\pi^r} V^{\pi^r}(s)\right]\]
\[= \mathbb{E}_g[V_g(x)]\]
Deterministic
problem for
each future
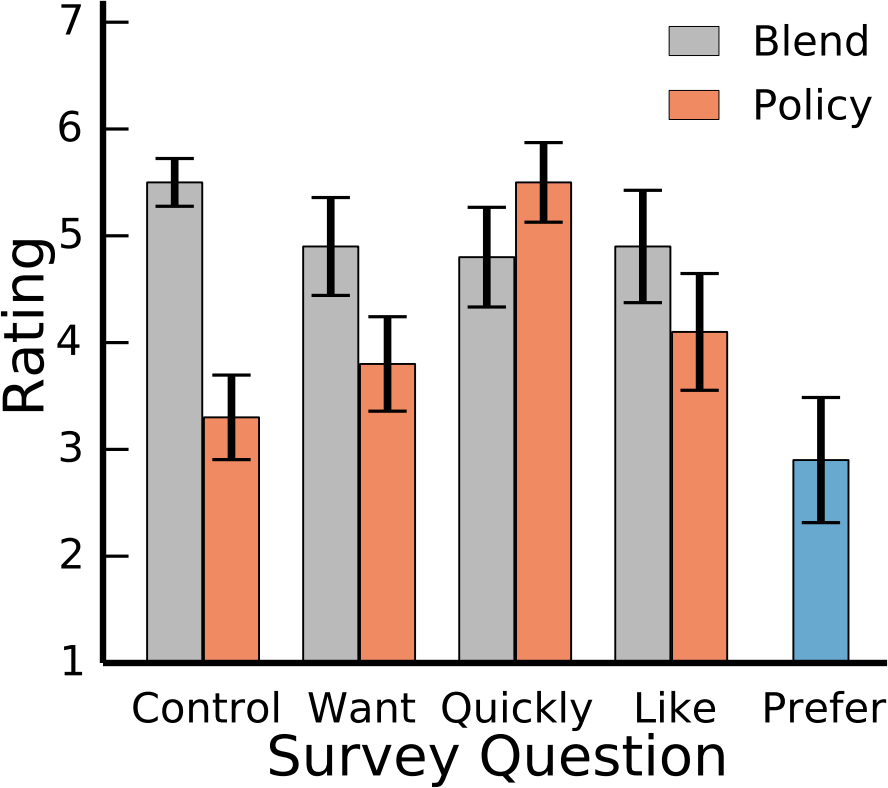
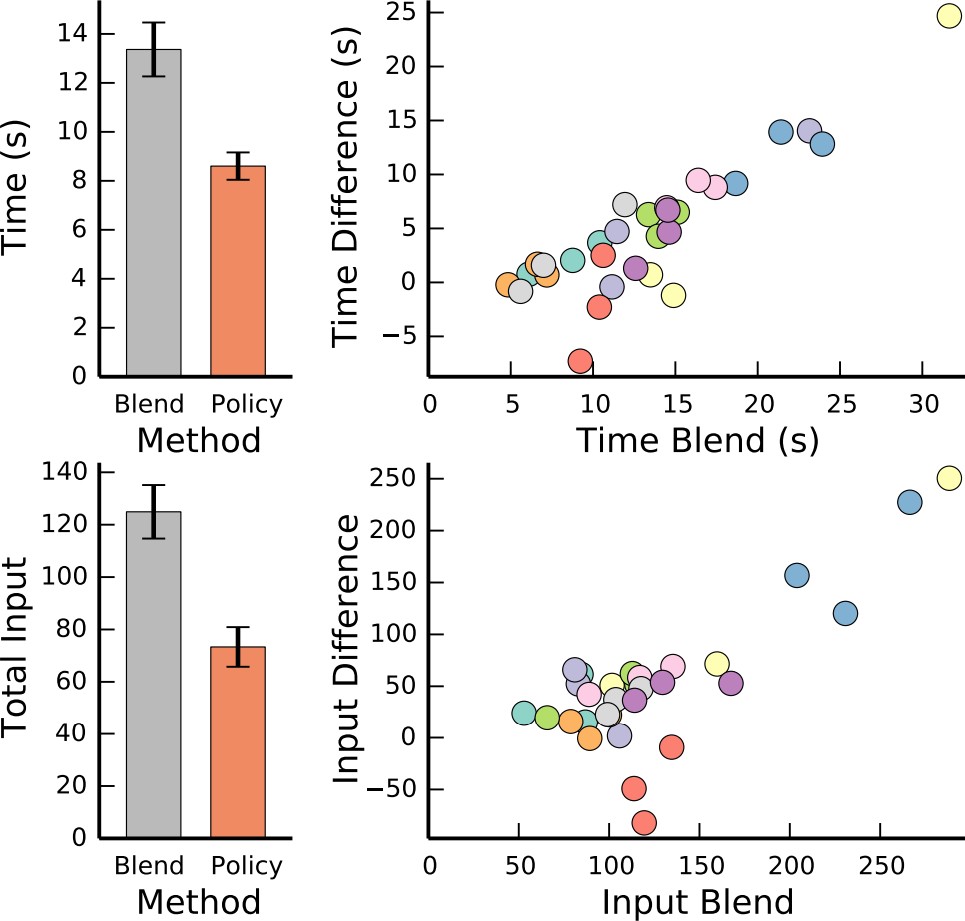
Compare with method that predicts one goal, the proposed method has:
Faster execution time
Fewer user inputs
Forward Kinematics
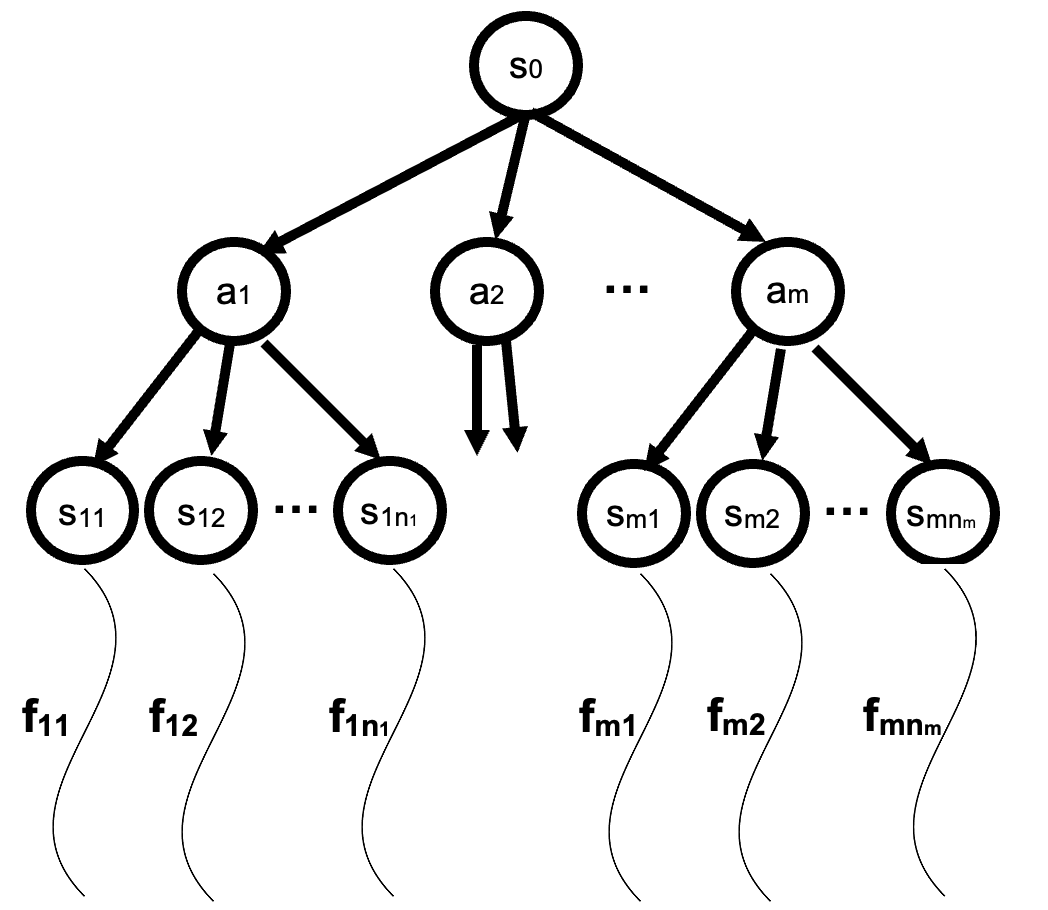
A common robotic skeleton is a tree of rigid bones
The relative Euler angles of all the joints determine the end-effector
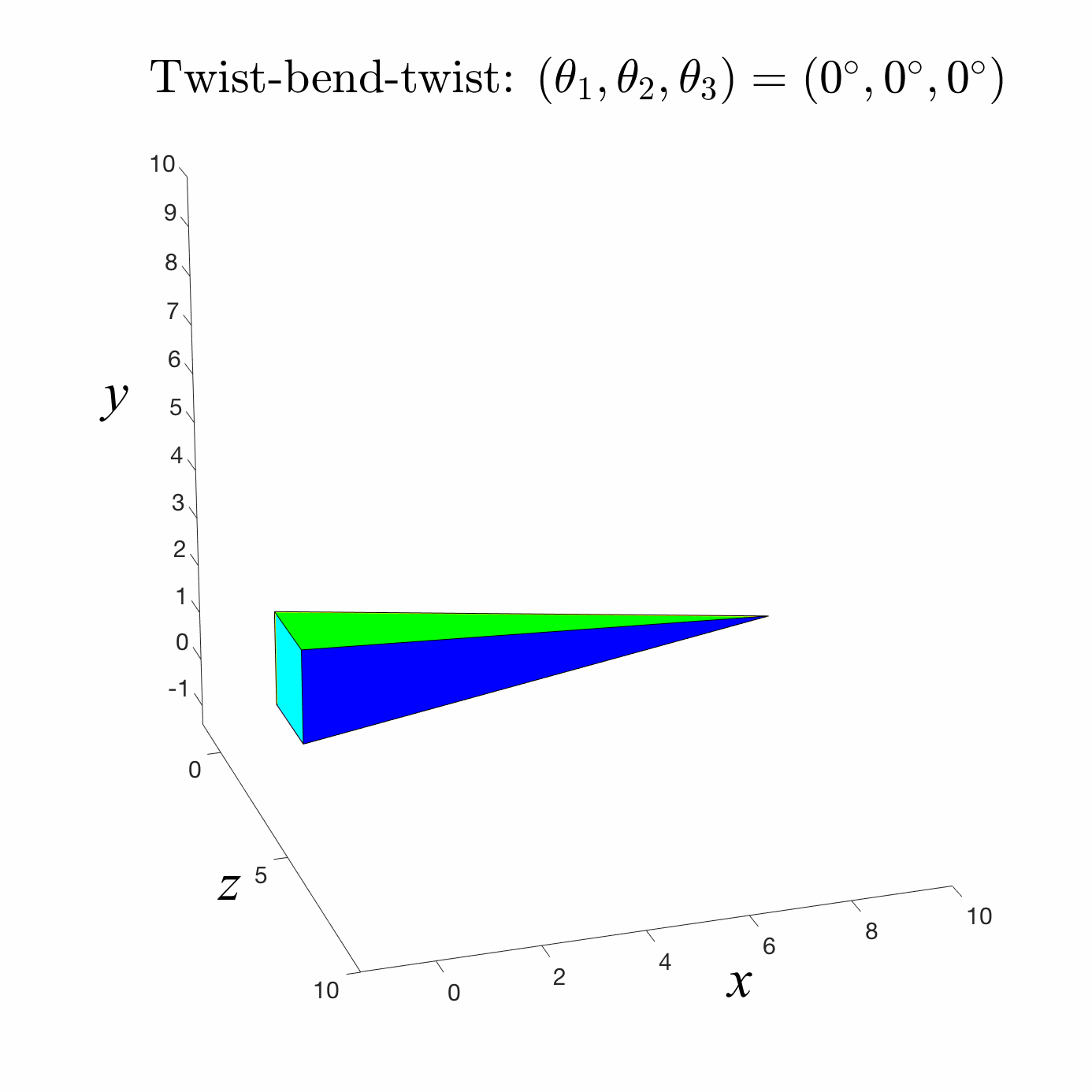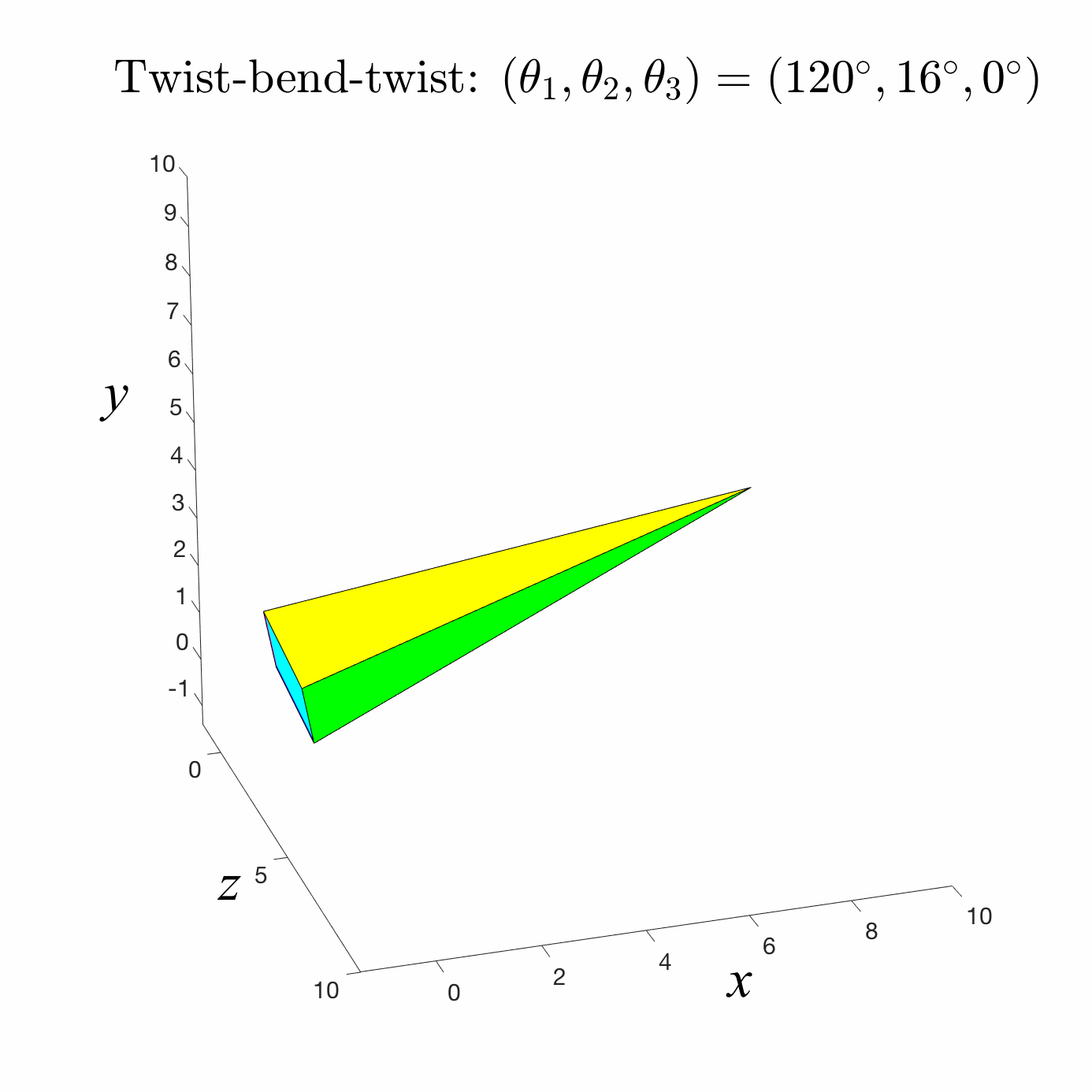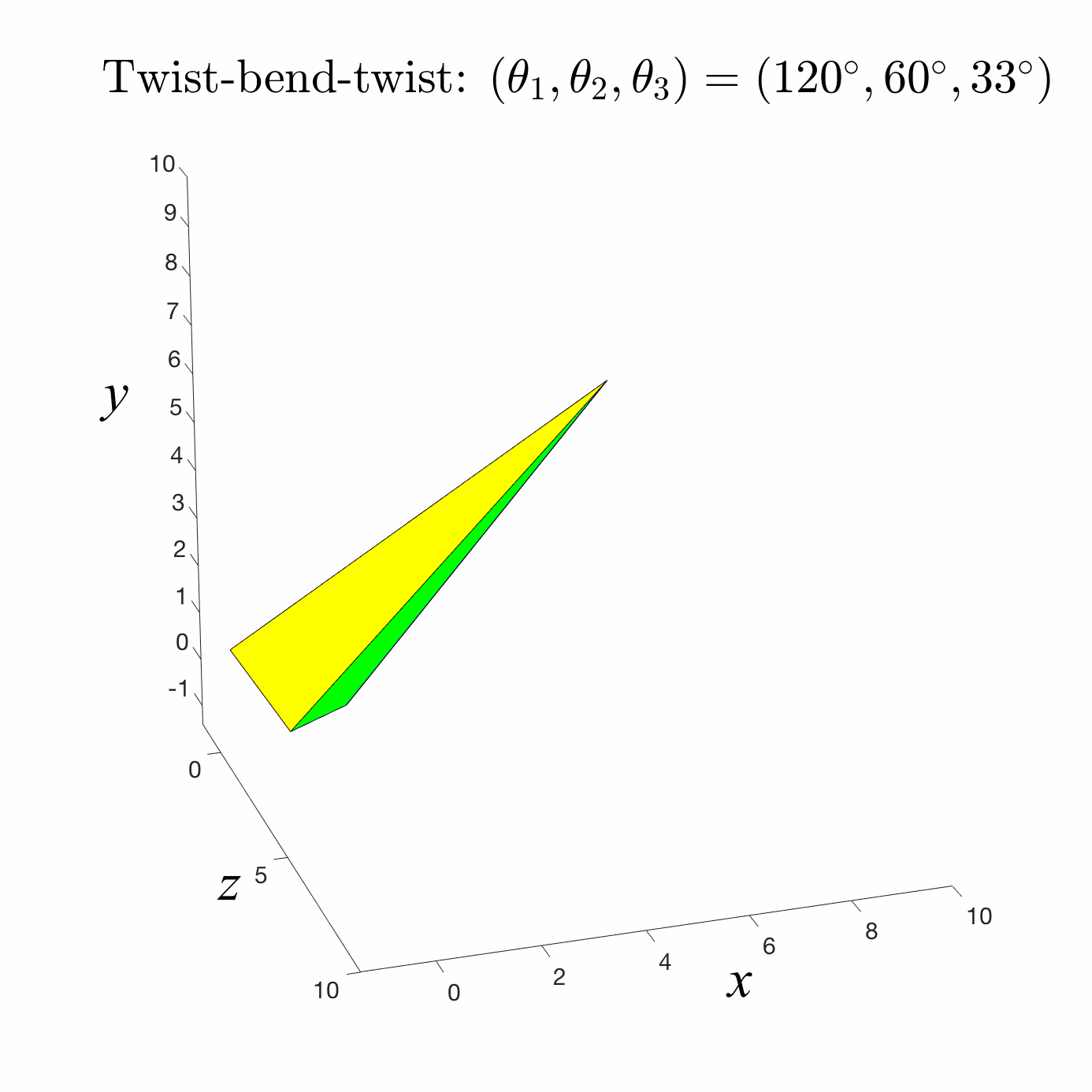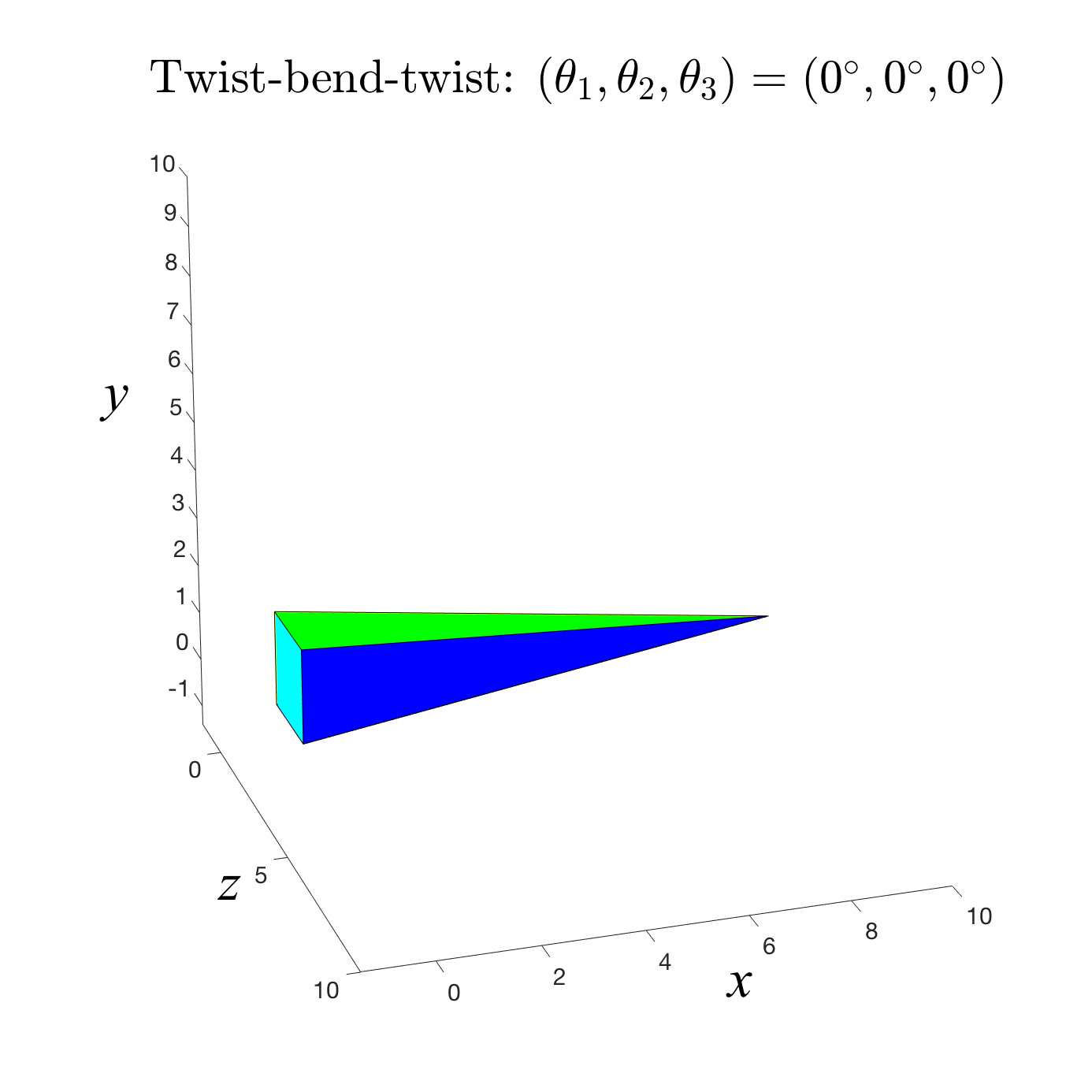
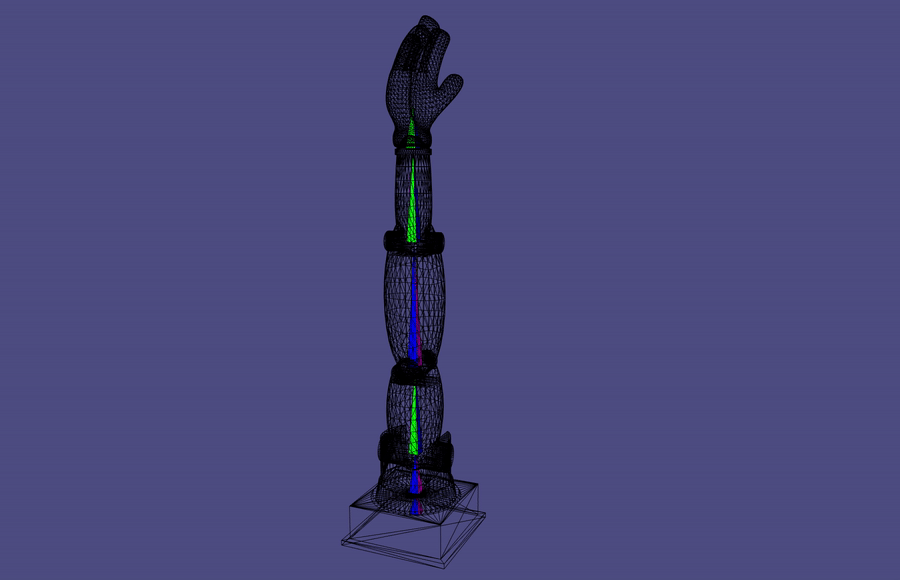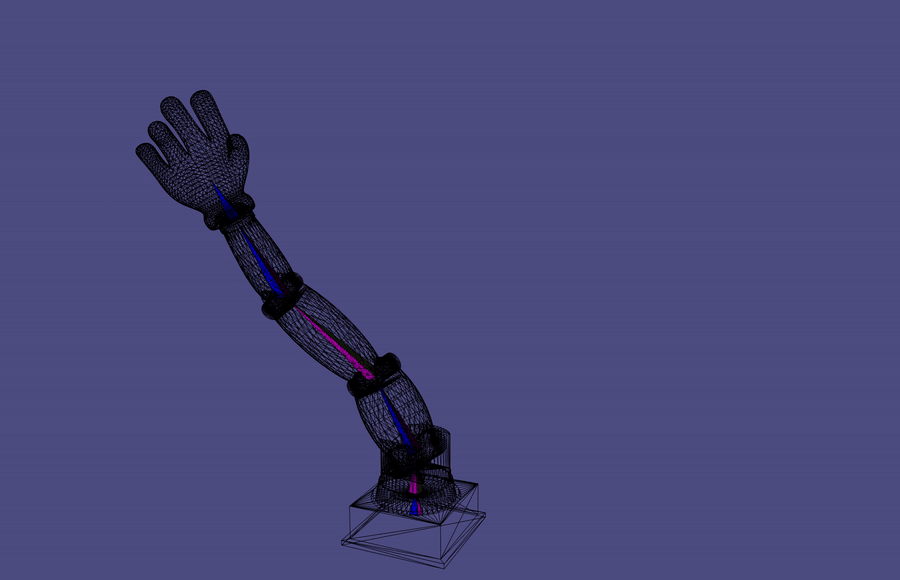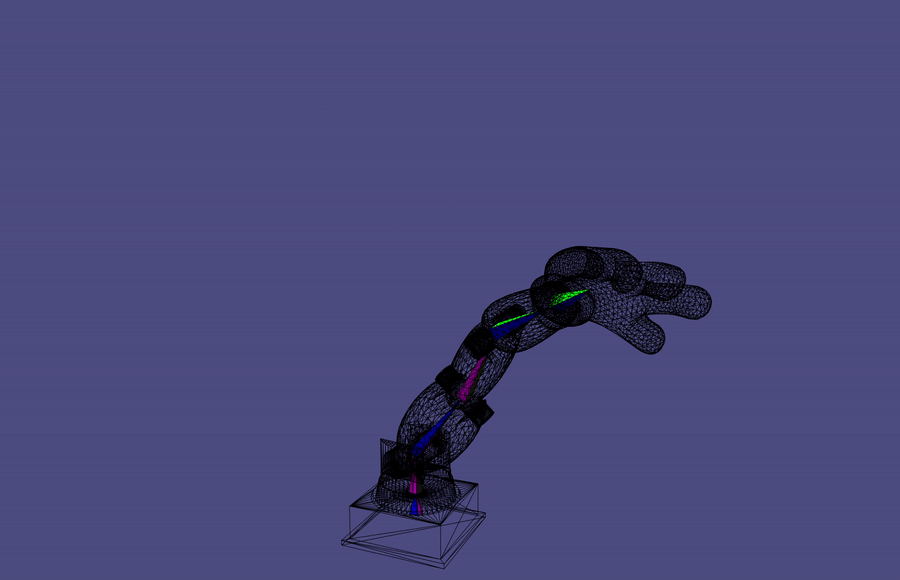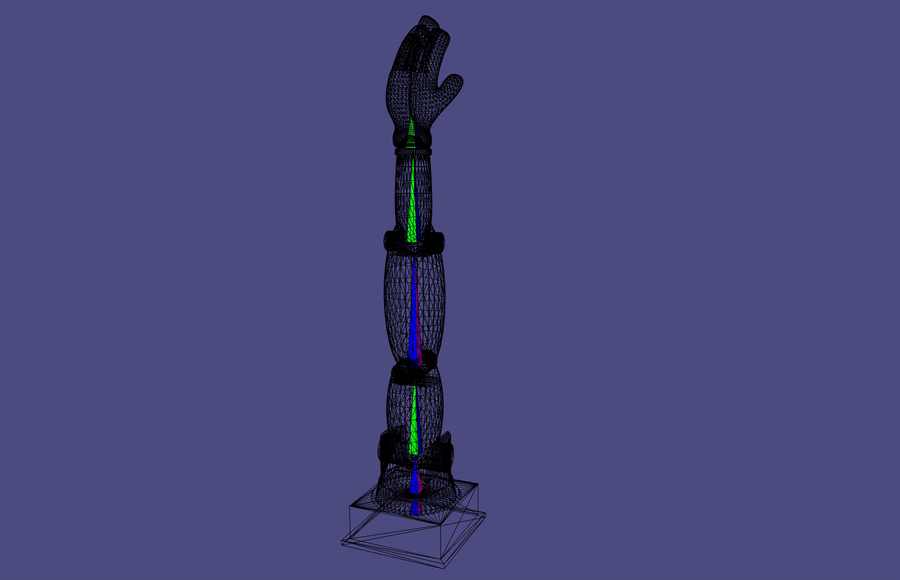
materials from https://github.com/alecjacobson/computer-graphics-csc418
Inverse Kinematics
We formulate the inverse kinematics function as: \(\Theta = IK(p)\) , which can be easily written in an analytic form for a simple tree skeleton.
Pose contains velocity?
Hard to find feasible state space?
In reality, IK is often treated as an optimization problem \[ \chi_p(\Theta) = \| p_g - FK(\Theta) \|_2 \]

Self-collision

Discontinuities

Goal mistracking
![]()
Unpredictable behaviors 
Self-collision loss
Common approach: very slow
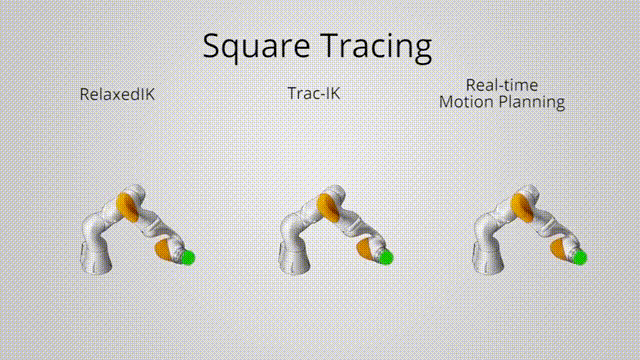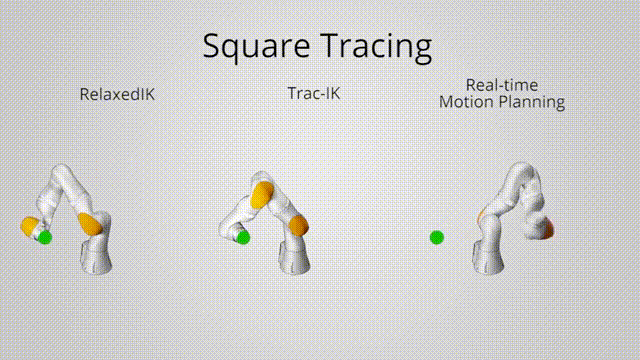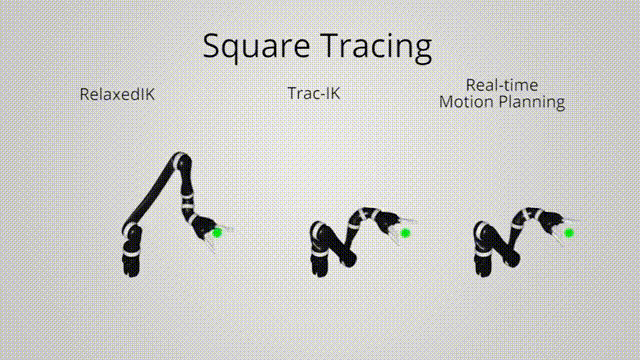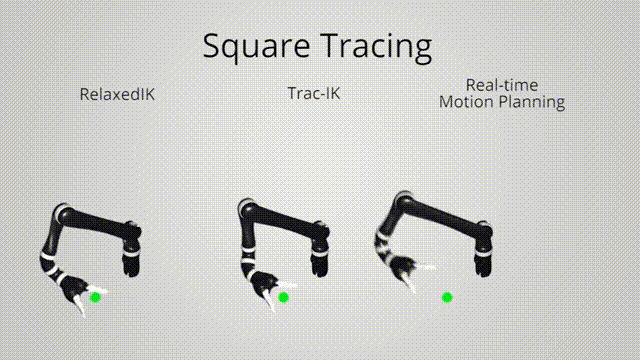
Relaxed IK:
Approximate how imminent the robot is to a collision state
Using simulated data to train a network to predict the distances between links
\[ \text{col}(\Theta) = \sum_{i,j} b \cdot \exp\left( -\frac{\text{dis}(l_i, l_j)^2}{2c^2} \right) \]

Pros