CSC2626 Imitation Learning for Robotics
Week 3: Offline/Batch Reinforcement Learning
Today’s agenda
• Reinforcement Learning Terminology
• Distribution Shift in Offline RL
• Offline RL with Policy Constraints
• Offline RL with Conservative Q-Estimates
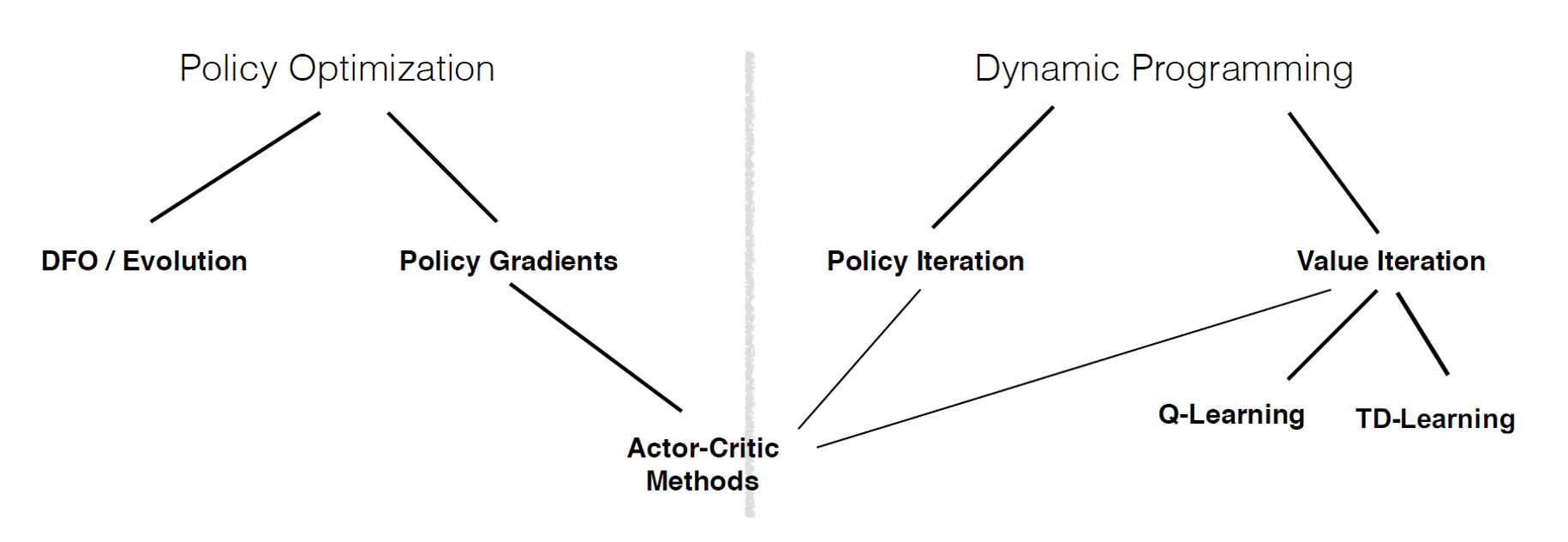
Policy Optimization vs Value Function Estimation
Credit: John Schulman
On-policy vs Off-policy Methods
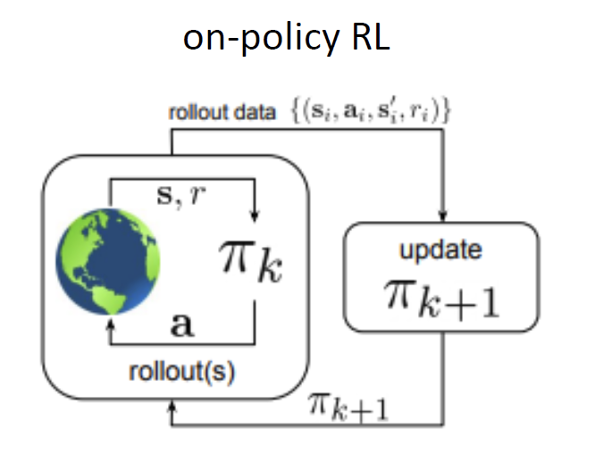
On-policy RL methods: improve the policy that acts on the environment using data collected from that same policy
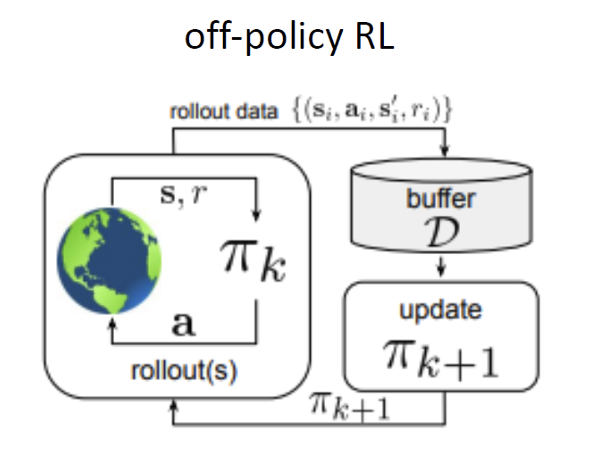
Off-policy RL methods: improve the policy that acts on the environment using data collected from any policy
Batch (Offline) vs Online Methods
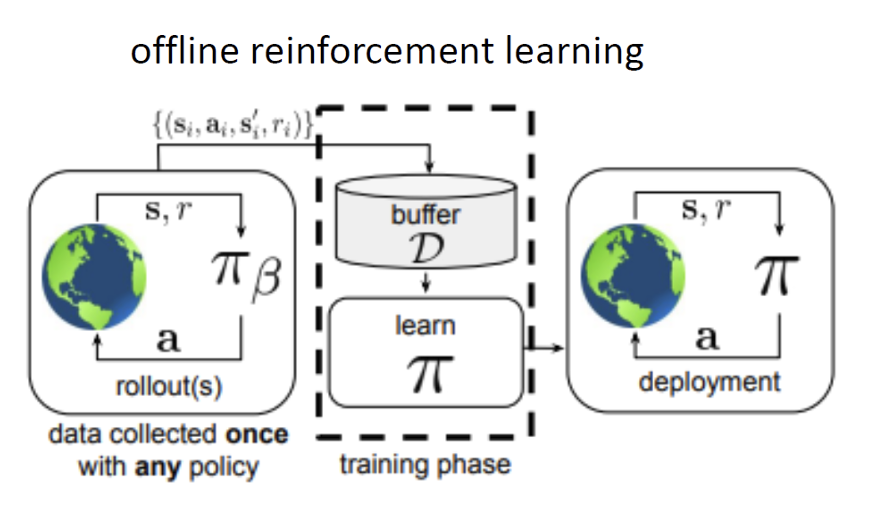
Online RL methods: Can collect data over multiple rounds. Data distribution changes over time.
Batch/Offline RL methods: Can collect data only once from any policy. Data distribution is stationary.
Batch (Offline) vs Online Methods
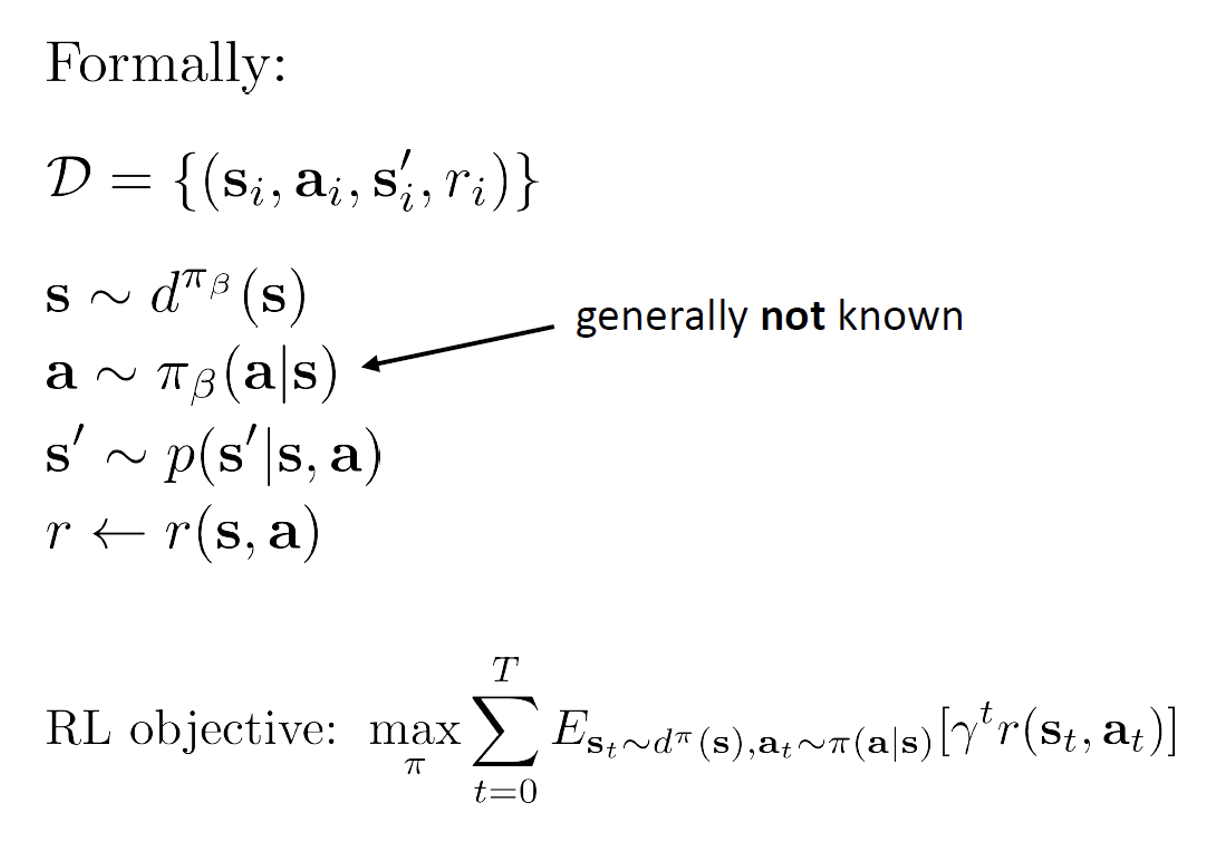

\(\mathbf{s} \in \mathcal{S}\) – discrete or continuous state
\(\mathbf{a} \in \mathcal{A}\) – discrete or continuous action
\(\tau = \{s_0, a_0, s_1, a_1, \ldots, s_T, a_T\}\) - trajectory
\(\underbrace{\pi(s_0, a_0, \ldots, s_T, a_T)}_{\pi(\tau)} = p(s_1) \prod_{t=0}^{T} \pi(a_t | s_t) p(s_{t+1} | s_t, a_t)\)
\(d_t^{\pi}(s_t)\) – state marginal of \(\pi(\tau)\) at \(t\)
\(d^{\pi}(s) = \frac{1}{1-\gamma} \sum_{t=0}^{T} \gamma^t d_t^{\pi}(s_t) \quad \text{– "visitation frequency"}\)
\(Q^{\pi}(s_t, a_t) = r(s_t, a_t) + \gamma \mathbb{E}_{s_{t+1} \sim p(s_{t+1} | s_t, a_t), a_{t+1} \sim \pi(a_{t+1} | s_{t+1})} \left[Q^{\pi}(s_{t+1}, a_{t+1})\right]\)
\(V^{\pi}(s_t) = \mathbb{E}_{a_t \sim \pi(a_t | s_t)} \left[Q^{\pi}(s_t, a_t)\right]\)
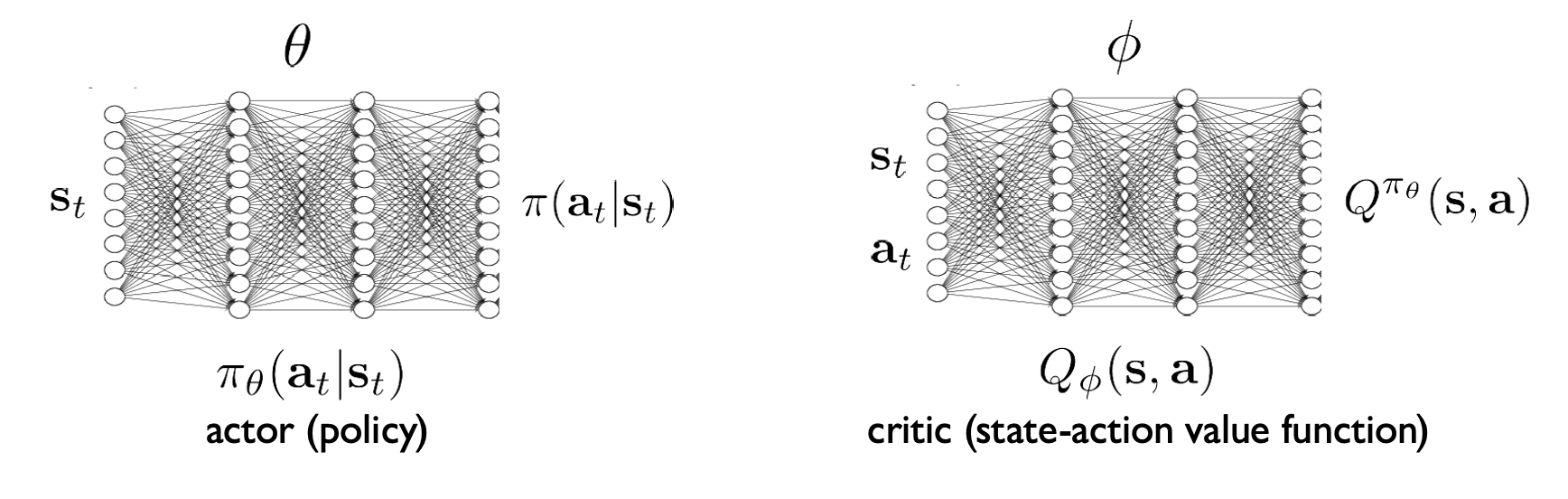
On-policy actor-critic with function approximation
![]()
- update \(Q_\phi\) to decrease \(E_{s \sim d^{\pi_\theta}(s), a \sim \pi_\theta(a|s)} \left[\left(Q_\phi(s,a) - (r(s,a) + \gamma E_{\pi_\theta}[Q_\phi(s',a')])\right)^2\right]\)
- update \(\pi_\theta\) to increase \(E_{s \sim d^{\pi_\theta}(s), a \sim \pi_\theta(a|s)} [Q_\phi(s,a)]\)
Off-policy actor-critic with function approximation
![]()
- update \(Q_\phi\) to decrease \(E_{s \sim d^{\pi_\beta}(s), a \sim \pi_\beta(a|s)} \left[\left(Q_\phi(s,a) - (r(s,a) + \gamma E_{\pi_\theta}[Q_\phi(s',a')])\right)^2\right]\)
- update \(\pi_\theta\) to increase \(E_{s \sim d^{\pi_\beta}(s), a \sim \pi_\theta(a|s)} [Q_\phi(s,a)]\)
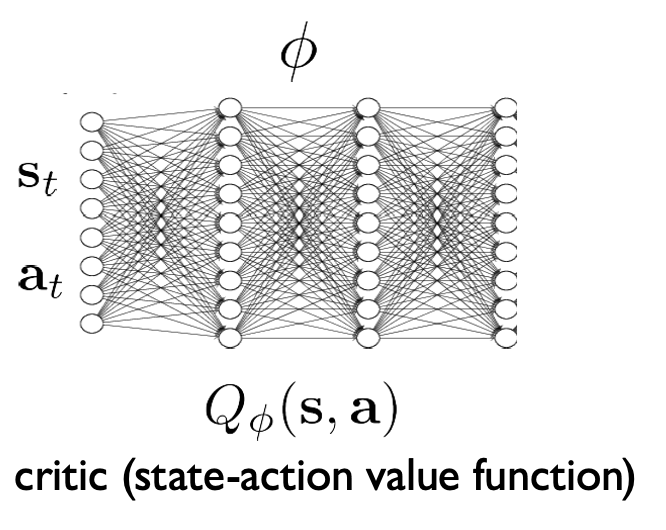
Q-Learning/Fitted Q-Iteration with function approximation (off-policy)
![]()
- update \(Q_\phi\) to decrease \(E_{s \sim d^{\pi_\beta}(s), a \sim \pi_\beta(a|s)} \left[\left(Q_\phi(s,a) - (r(s,a) + \gamma E_{\pi_\theta}[Q_\phi(s',a')])\right)^2\right]\)
update\(\pi_\theta\) to increase \(E_{s \sim d^{\pi_\beta}(s), a \sim \pi_\theta(a|s)} [Q_\phi(s,a)]\)
choose \(\pi\) according to: \(\pi(a_t | s_t) = \begin{cases} 1 & \text{if } a_t = \arg\max_{a_t} Q_\phi(s_t, a_t) \\ 0 & \text{otherwise} \end{cases}\)



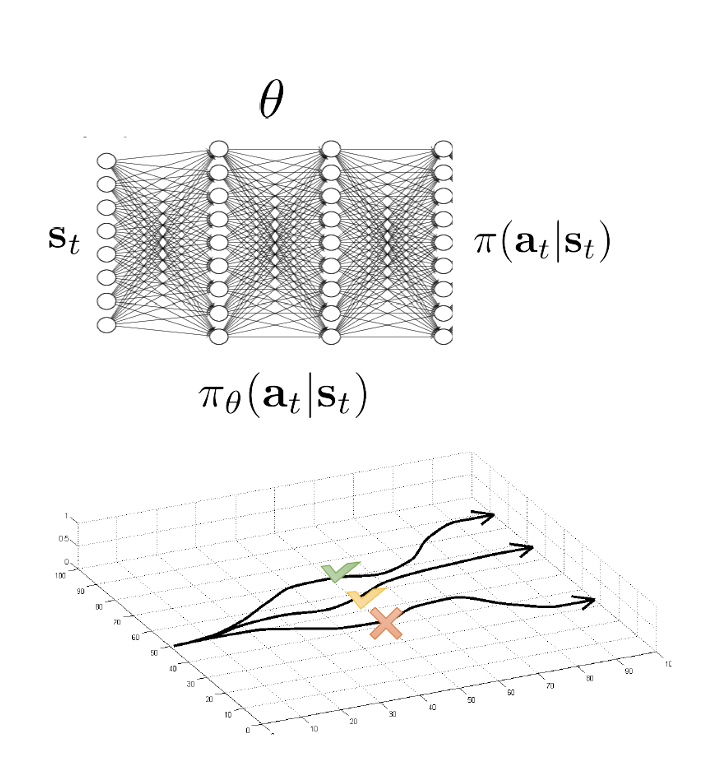
Policy gradients (on-policy)
RL objective: \(\max_{\pi} \sum_{t=0}^{T} E_{s_t \sim d^{\pi}(s), a_t \sim \pi(a|s)} [\gamma^t r(s_t, \mathbf{a}_t)]\)
\(\qquad \qquad \qquad \qquad \qquad \nearrow\) exactly the same thing!
\(J(\theta) = E_{\tau \sim \pi_\theta(\tau)} \left[\sum_{t=0}^{T} \gamma^t r(s_t, a_t)\right] \approx \frac{1}{N} \sum_{i=1}^{N} \sum_{t=0}^{T} \gamma^t r(s_{t,i}, a_{t,i})\)
\(\nabla_\theta J(\theta) = E_{\tau \sim \pi_\theta(\tau)} \left[\nabla_\theta \log \pi_\theta(\tau) \sum_{t=0}^{T} \gamma^t r(s_t, \mathbf{a}_t)\right] \text{ simple algebraic derivation}\)
(REINFORCE gradient estimator)
Today’s agenda
• Reinforcement Learning Terminology
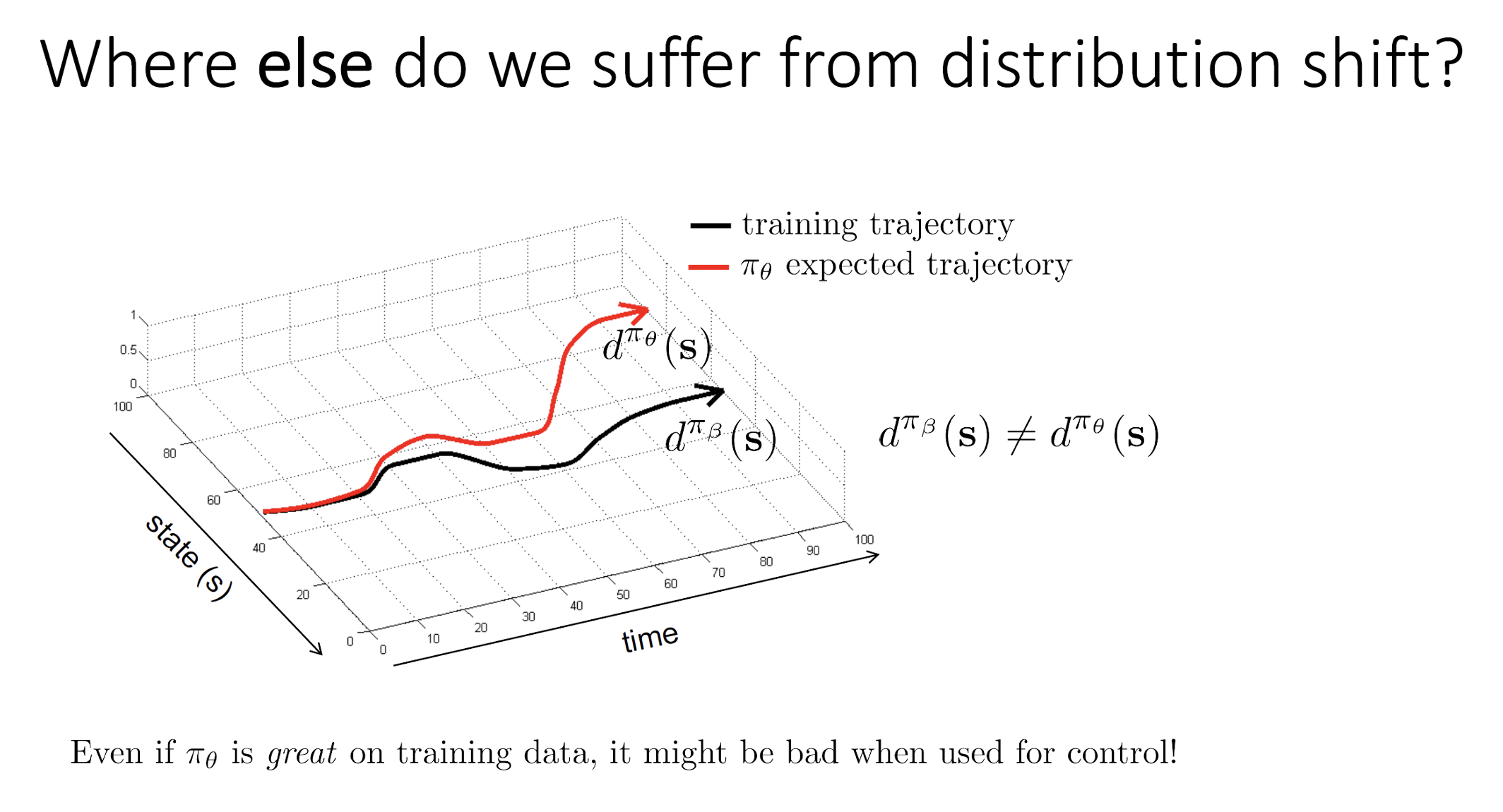
• Distribution Shift in Offline RL
• Offline RL with Policy Constraints
• Offline RL with Conservative Q-Estimates
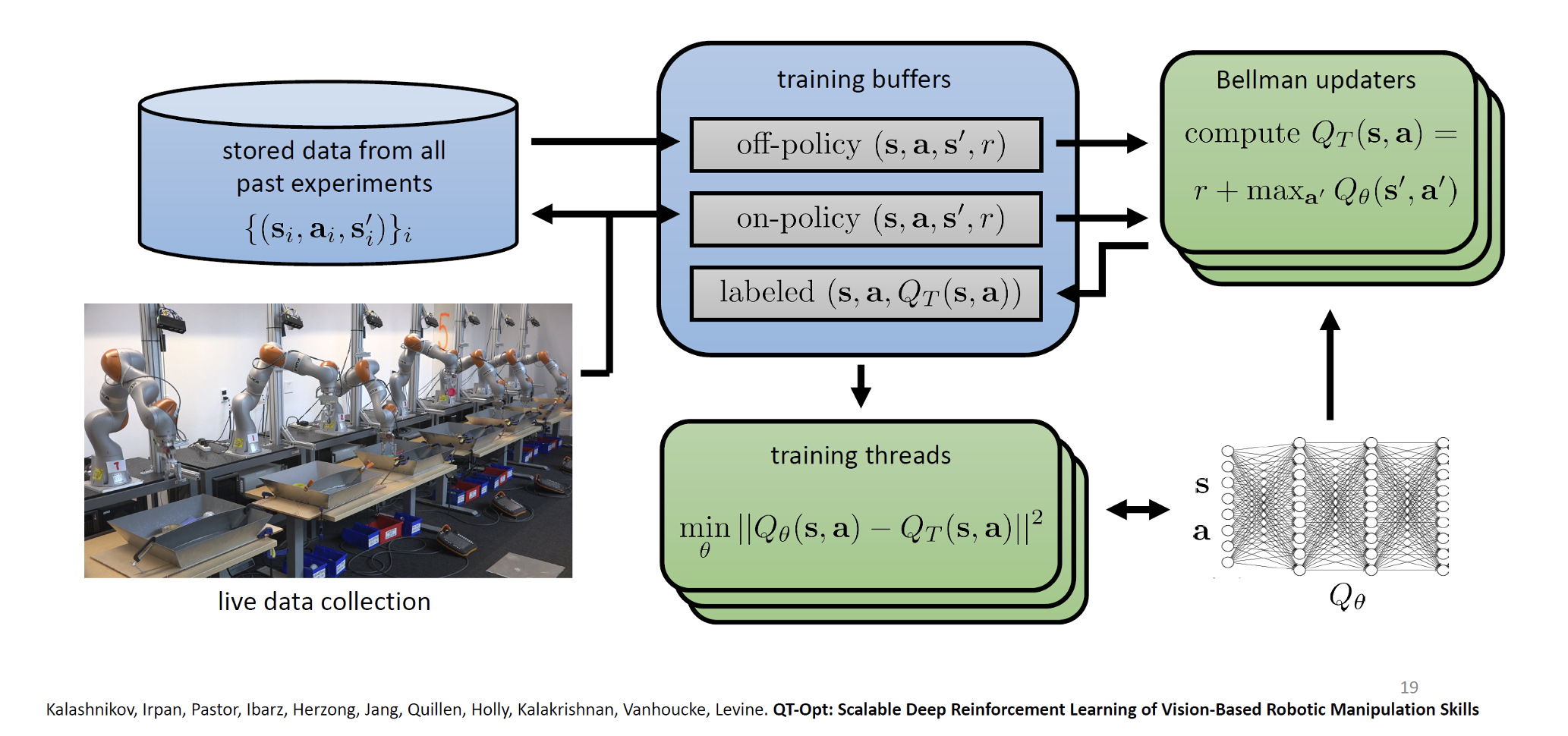
QT-Opt (roughly: continuous-action Q-Learning)

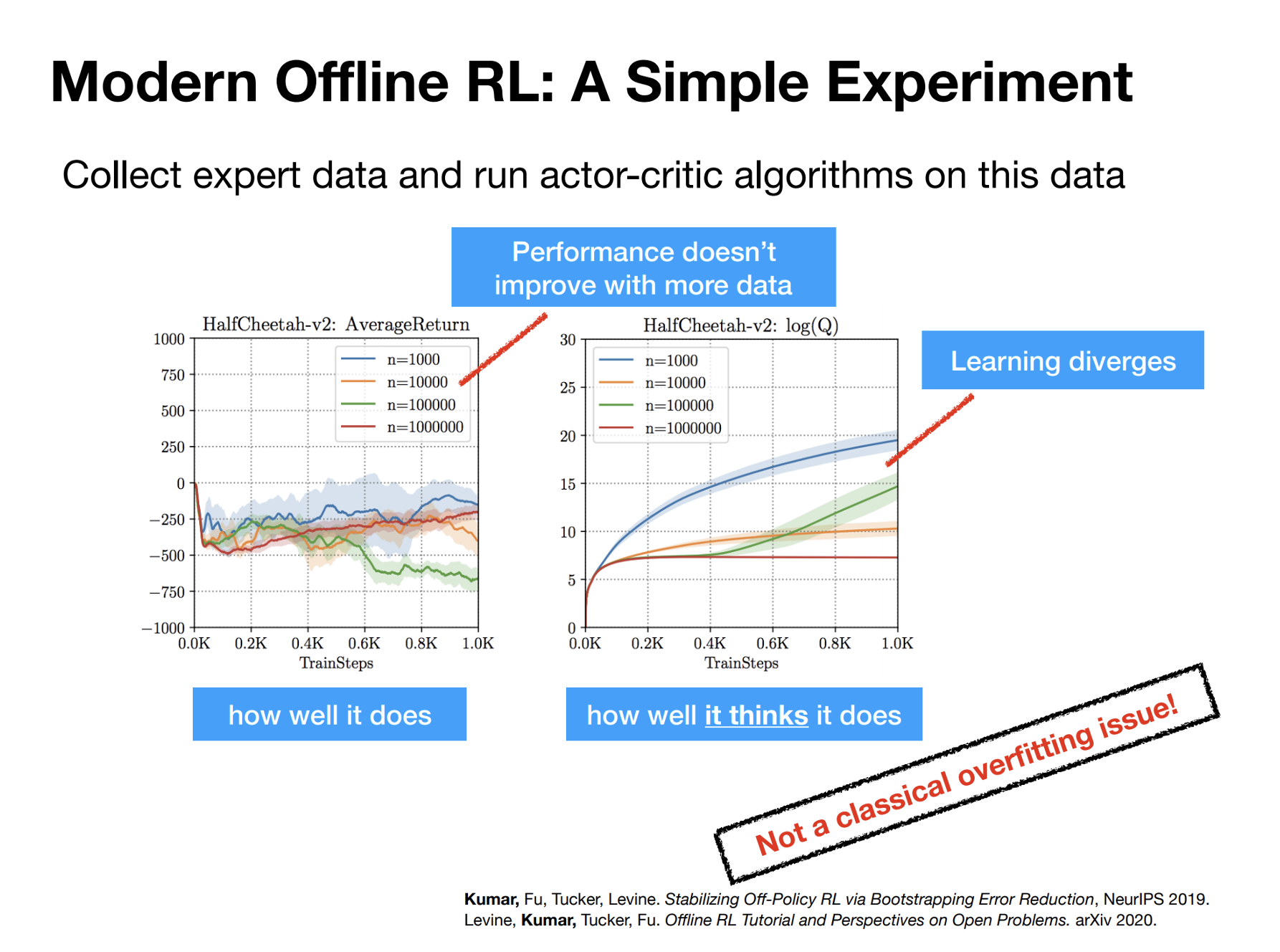
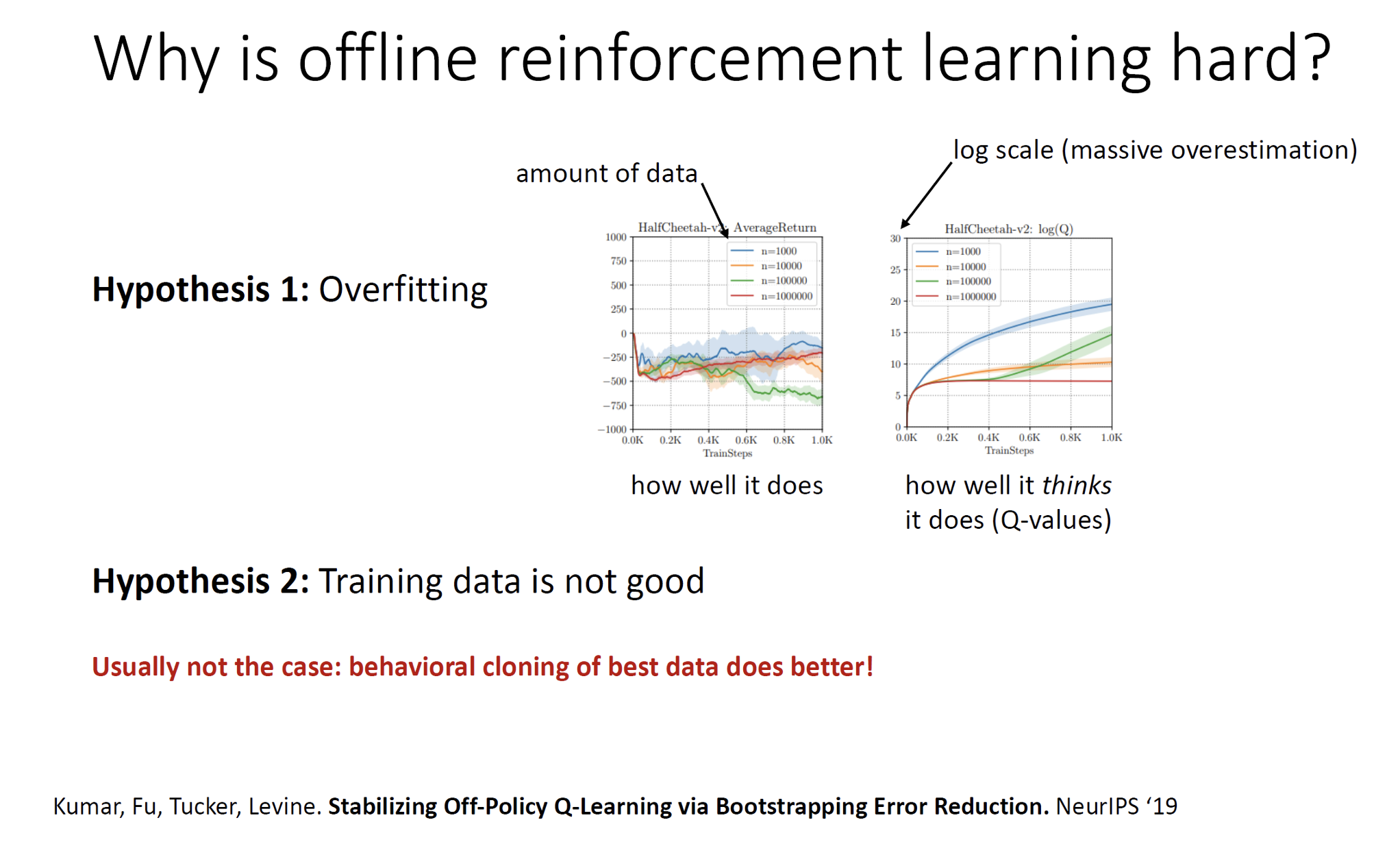




Today’s agenda
• Reinforcement Learning Terminology
• Distribution Shift in Offline RL
• Offline RL with Policy Constraints
• Offline RL with Conservative Q-Estimates
Addressing Distribution Shift via Pessimism
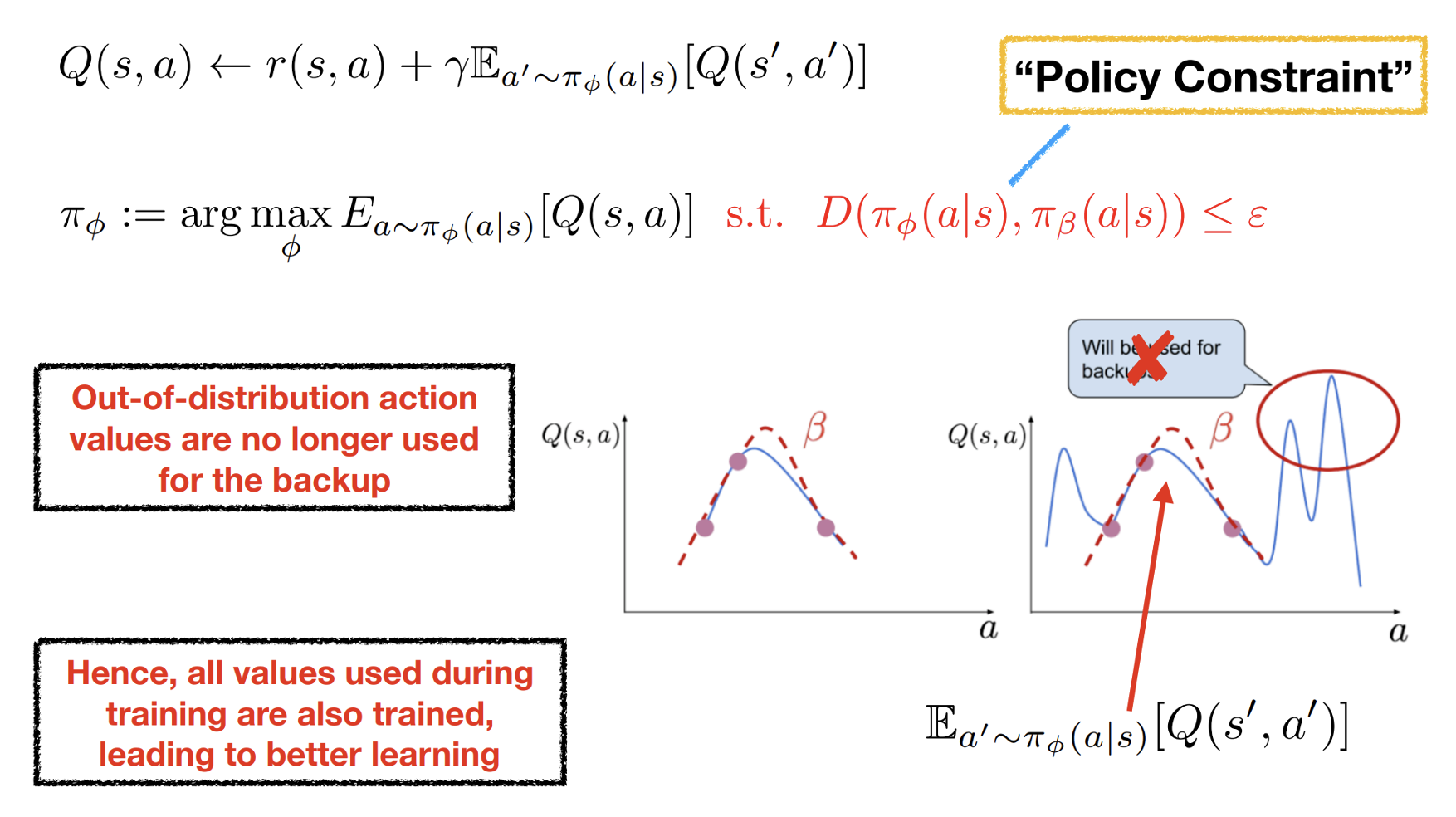
Different Types of Policy Constraint Methods

Note: KL divergence is not symmetric
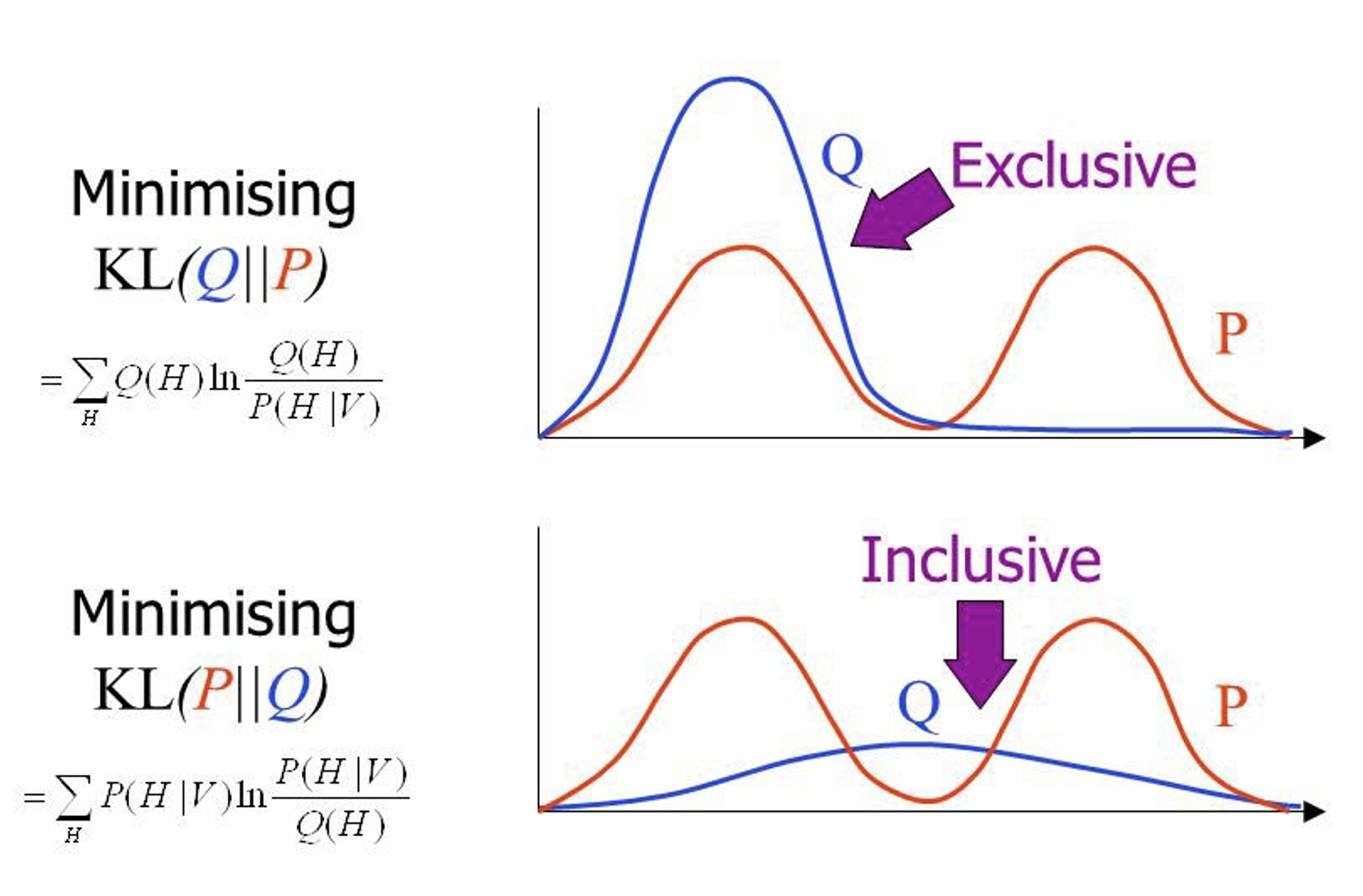

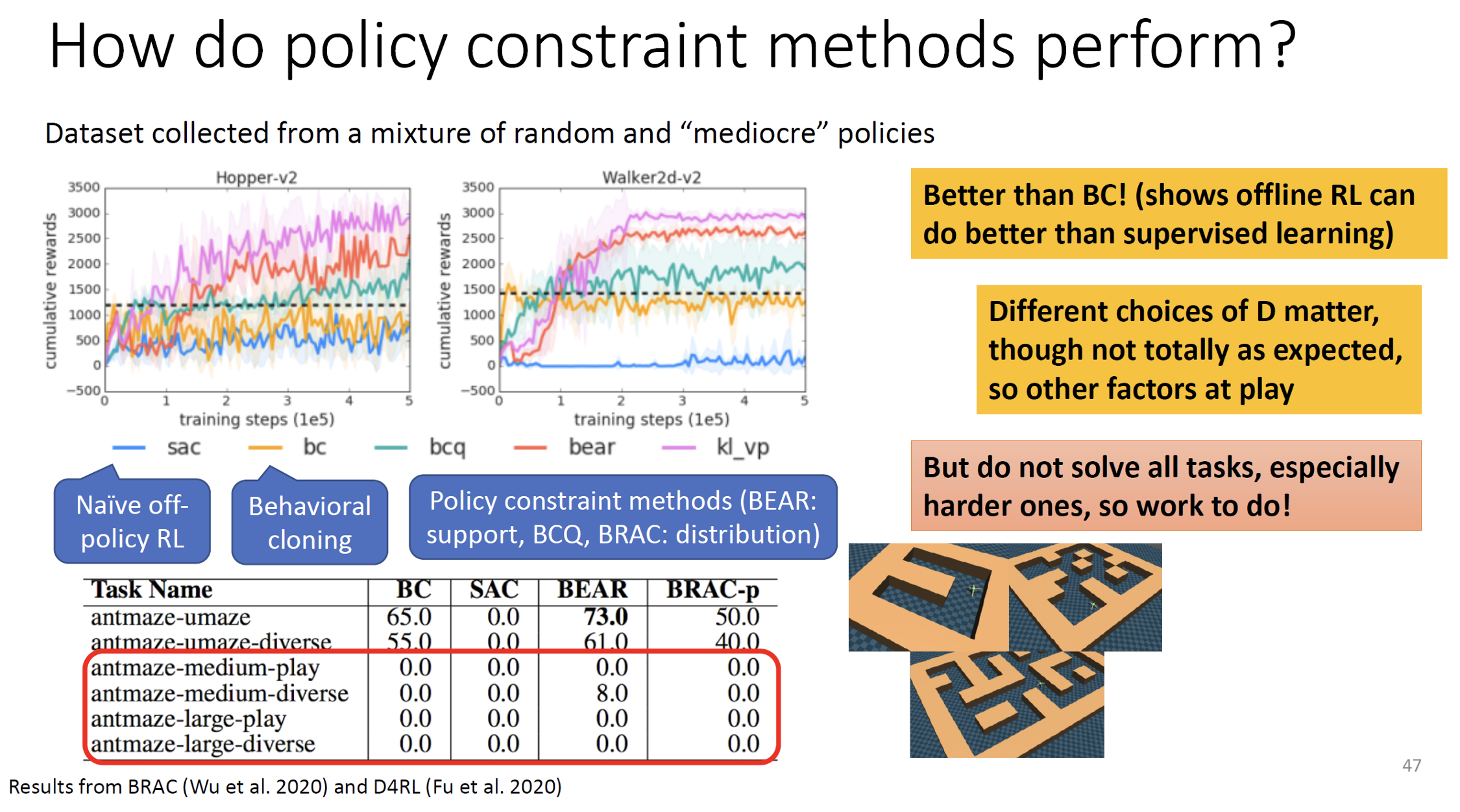
How should we evaluate offline RL methods

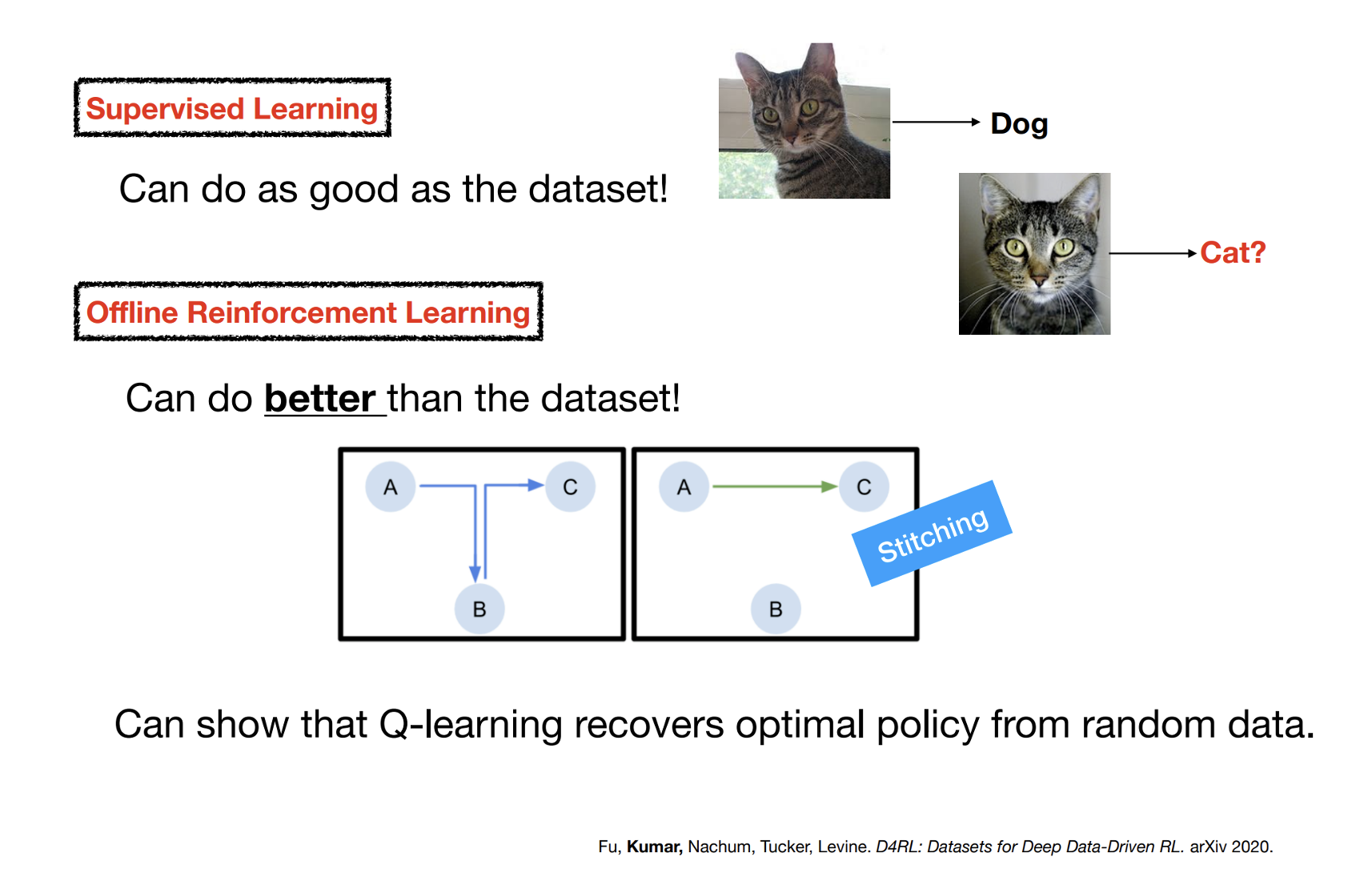
Evaluating Offline RL – D4RL

Evaluating Offline RL – D4RL

Standardized Benchmark for Offline RL

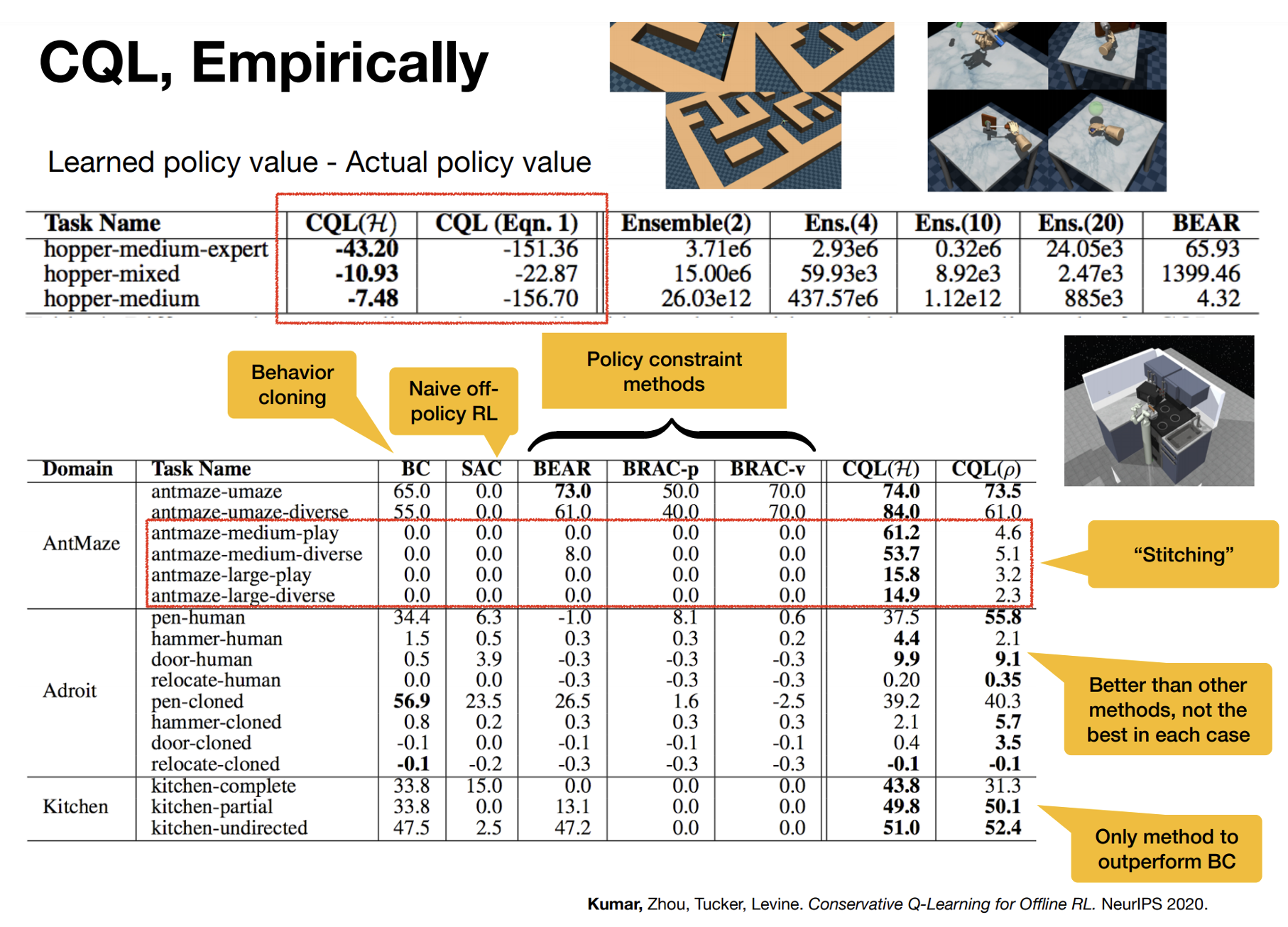
Value Function Regularization for Offline RL

Learning Lower-Bounded Q-values

A Tighter Lower Bound

Practical CQL Algorithm

The need for safe exploration in RL for robotics


When applying RL to robotics we need to guarantee that the algorithm will not visit unsafe states very often during learning.
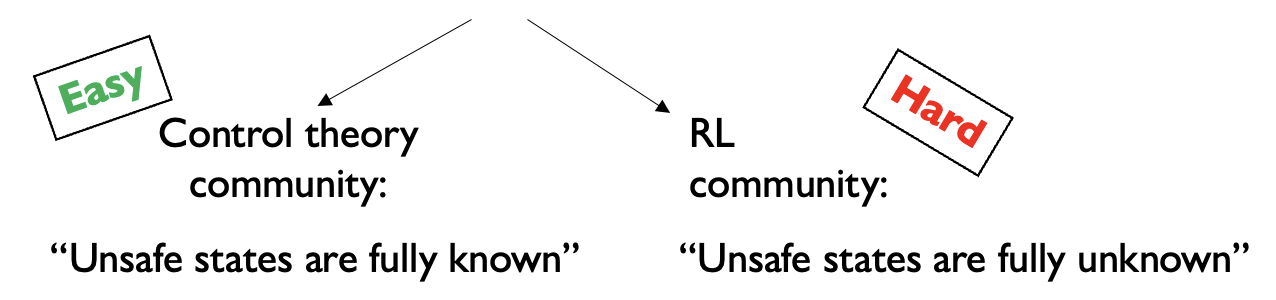
The need for safe exploration in RL for robotics
When applying RL to robotics we need to guarantee that the algorithm will not visit unsafe states very often during learning.

The need for safe exploration in RL for robotics
When applying RL to robotics we need to guarantee that the algorithm will not visit unsafe states very often during learning.
Our proposed method:
The learned policy should be safe at each iteration, not just when optimization has converged
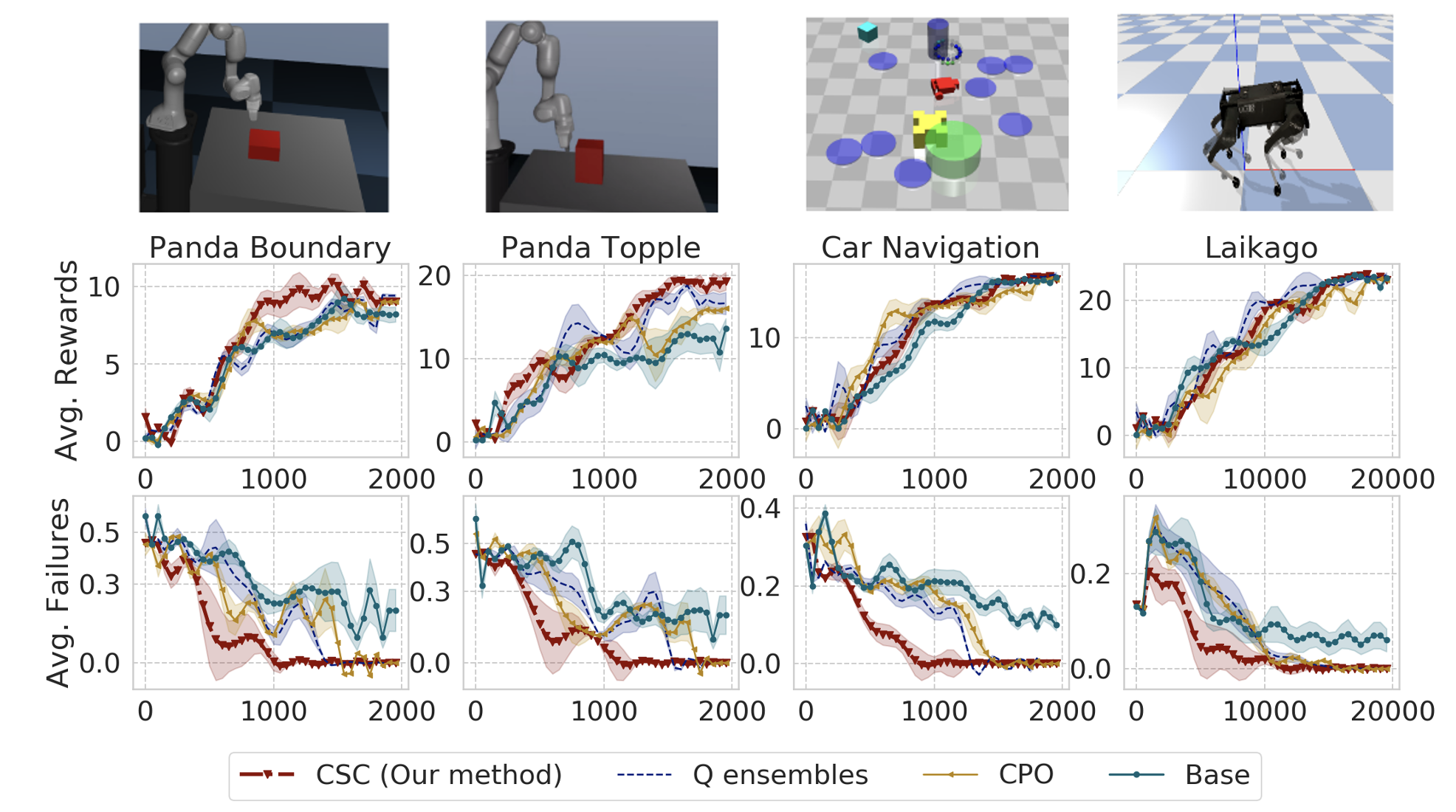
Results: fewer accidents
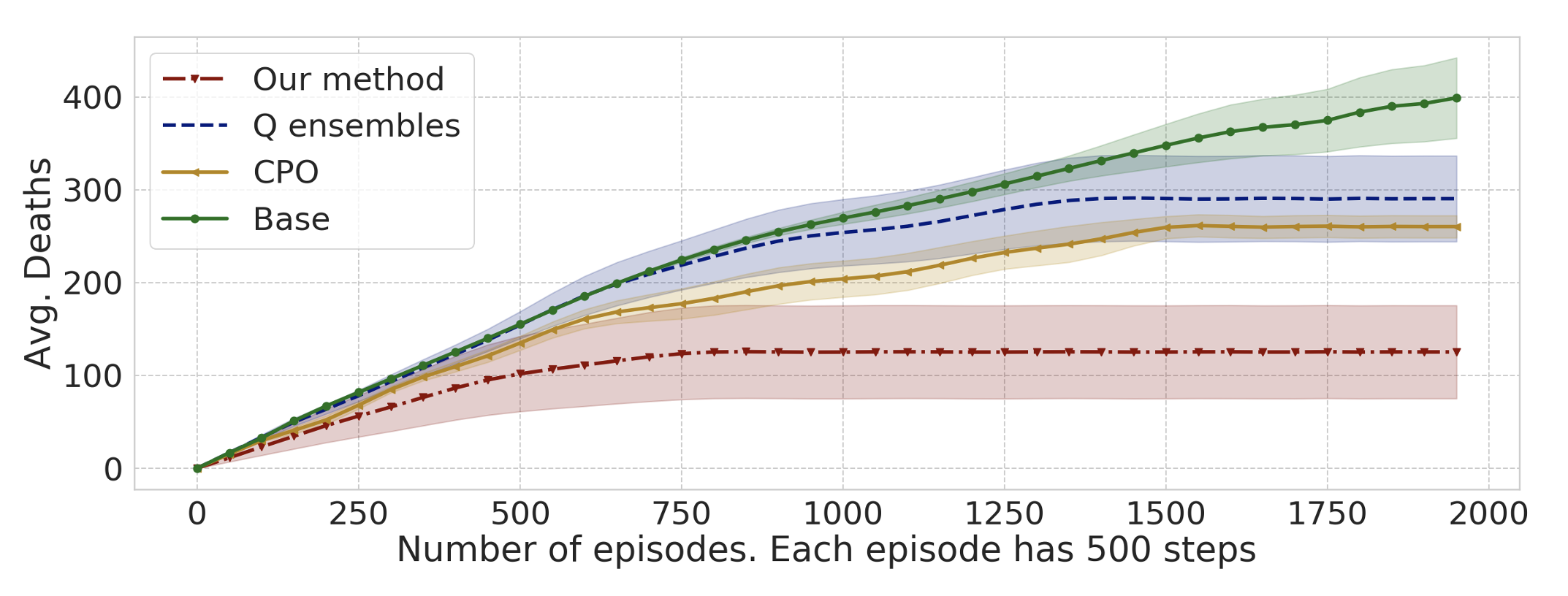
Constrained Policy Optimization, https://arxiv.org/abs/1705.10528, Achiam, Held, Tamam, Abbeel
Results: task value vs safety