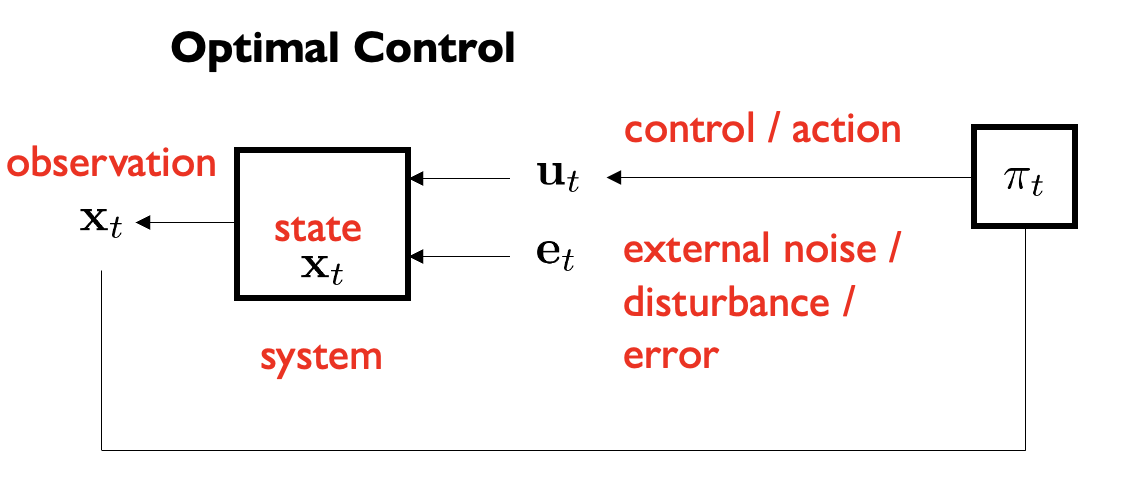
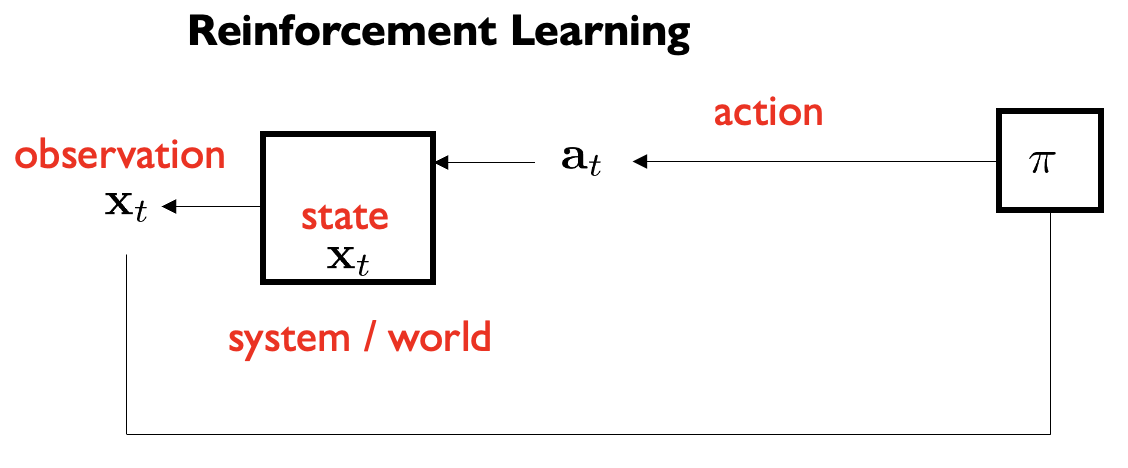
Week 2: Introduction to Optimal Control & Model-Based RL
Florian Shkurti
Today’s agenda
• Intro to Control & Reinforcement Learning
• Linear Quadratic Regulator (LQR)
• Iterative LQR
• Model Predictive Control
• Learning dynamics and model-based RL
\(\qquad \qquad \qquad \uparrow\)
Optimal state-action value function:
“if you land at state x, and you commit
to first execute action a, and then
follow the optimal policy how much
reward will you accumulate?”
\[
\textcolor{red}{\swarrow \text{For finite time horizon} \searrow}
\]
State-action value function of policy pi:
“if you land at state x, and you commit
to first execute action a, and then follow
policy pi how much reward will you
accumulate?”
\[
\textcolor{red}{\swarrow \text{For finite time horizon} \searrow}
\]
• Intro to Control & Reinforcement Learning
• Linear Quadratic Regulator (LQR)
• Iterative LQR
• Model Predictive Control
• Learning dynamics and model-based RL
What you can do with (variants of) LQR control
What you can do with (variants of) LQR control
Pieter Abbeel, Helicopter Aerobatics
LQR: assumptions
• You know the dynamics model of the system
• It is linear: \(\mathbf{x}_{t+1} = A\mathbf{x}_t + B\mathbf{u}_t\)
\(\qquad \qquad \qquad \qquad \uparrow\)
State at the next time step
\[
\mathbb{R}^d
\]
\[
A \in \mathbb{R}^{d \times d}
\]
\(\qquad \uparrow\)
Control / command / action applied to the system
\[
\mathbb{R}^k
\]
\[
B \in \mathbb{R}^{d \times k}
\]
Which systems are linear?
✓ • Omnidirectional robot
\[
\begin{align}
x_{t+1} &= x_t + v_x(t)\delta t \\
y_{t+1} &= y_t + v_y(t)\delta t \\
\theta_{t+1} &= \theta_t + \omega_z(t)\delta t
\end{align}
\quad \Rightarrow \quad
\]
\[
\mathbf{x}_{t+1} = I\mathbf{x}_t + \delta t I \mathbf{u}_t
\]\[
\begin{align}
A &= I \\
B &= \delta t I
\end{align}
\]
X • Simple Car
\[
\begin{align}
x_{t+1} &= x_t + v_x(t)\cos(\theta_t)\delta t \\
y_{t+1} &= y_t + v_x(t)\sin(\theta_t)\delta t \\
\theta_{t+1} &= \theta_t + \omega_z\delta t
\end{align}
\quad \Rightarrow \quad
\]
\[
\mathbf{x}_{t+1} = I\mathbf{x}_t + \begin{bmatrix}
\delta t\cos(\theta_t) & 0 & 0 \\
0 & \delta t\sin(\theta_t) & 0 \\
0 & 0 & \delta t
\end{bmatrix} \mathbf{u}_t
\]\[
\begin{align}
A &= I \\
B &= B(x_t) \\
\end{align}
\]
The goal of LQR
If we want to stabilize around \(x^*\) then let \(x\) – \(x^*\) be the state \(\downarrow\)
• Stabilize the system around state \(x_t = 0\) with control \(u_t = 0\)
• Then \(x_{t+1} = 0\) and the system will remain at zero forever
LQR: assumptions
• You know the dynamics model of the system
• It is linear: \(\mathbf{x}_{t+1} = Ax_t + Bu_t\)
• There is an instantaneous cost associated with being at state \(x_t\) and taking the action : \(\mathbf{u}_t: c(\mathbf{x}_t, \mathbf{u}_t) = \mathbf{x}_t^T Q \mathbf{x}_t + \mathbf{u}_t^T R \mathbf{u}_t\)
\(\color{red}\uparrow\) Quadratic state cost: Penalizes deviation from the zero vector
\(\color{red}\nwarrow\) Quadratic control cost: Penalizes high control signals
\(\color{red}\uparrow\)
\(\color{red}\nearrow\)
Square matrices Q and R must be positive definite: \(Q = Q^T\) and \(\forall x, x^T Q x > 0\) \(R = R^T\) and \(\forall u, u^T R u > 0\) i.e. positive cost for ANY nonzero state and control vector
Finite-Horizon LQR
• Idea: finding controls is an optimization problem
• Compute the control variables that minimize the cumulative cost
We could solve this as a constrained nonlinear optimization problem. But, there is a better way: we can find a closed-form solution.
Open-loop plan!
Given first state compute action sequence
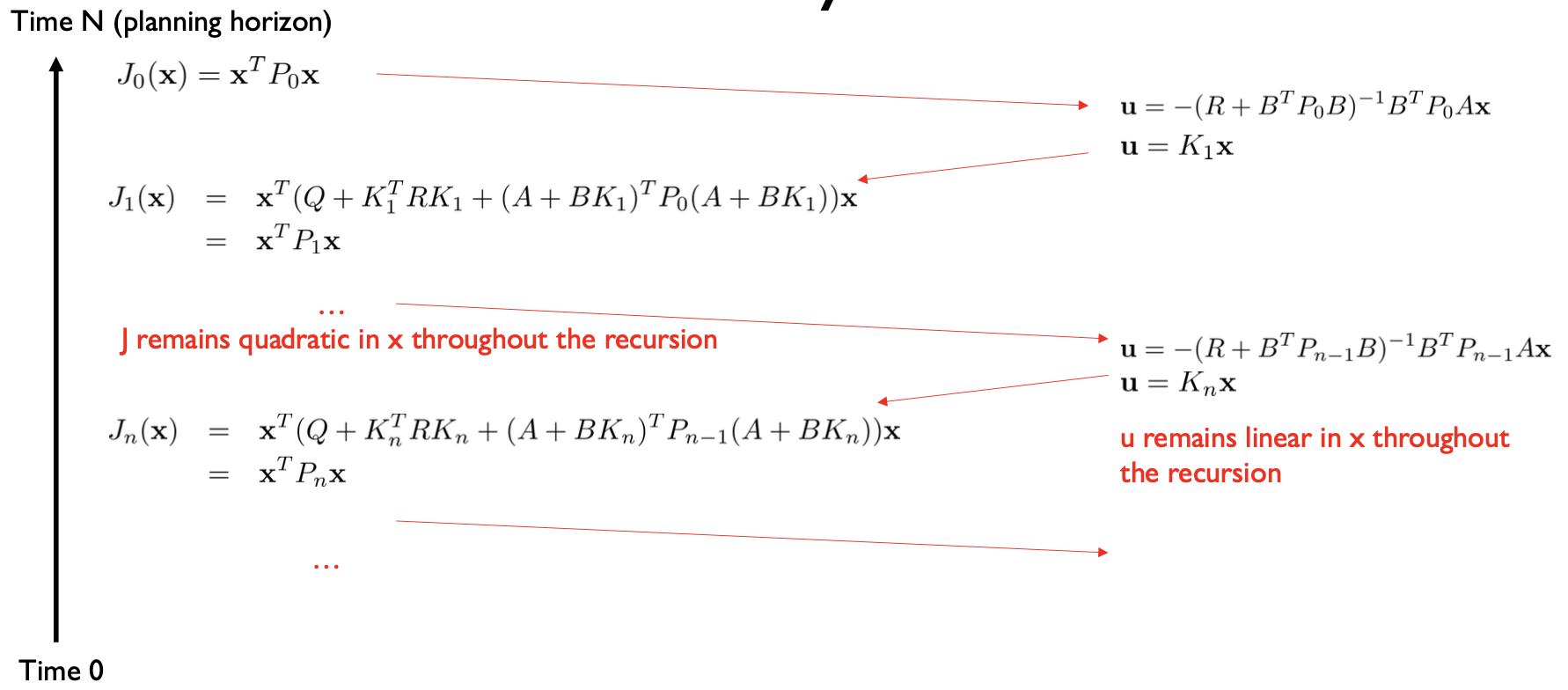
Finding the LQR controller in closed-form by recursion
• Let \(J_n(x)\) denote the cumulative cost-to-go starting from state x and moving for n time steps.
• I.e. cumulative future cost from now till n more steps
• \(J_0(x) = x^TQx\) is the terminal cost of ending up at state x, with no actions left to perform. Recall that \(c(x, u) = x^TQx + \cancel{\mathbf{u}^T R \mathbf{u}}\)
Q: What is the optimal cumulative cost-to-go function with 1 time step left?
Finding the LQR controller in closed-form by recursion
\(J_0(x) = x^TQx\)
For notational convenience later on
\[\begin{align}
J_1(\mathbf{x}) &= \min_{\mathbf{u}} \underbrace{[\mathbf{x}^T Q \mathbf{x} + \mathbf{u}^T R \mathbf{u} + J_0(A\mathbf{x} + B\mathbf{u})]}_{\color{red}\textbf{In RL this would be the state-action value function}} \\
\end{align}\]
Bellman Update
Dynamic Programming Value Iteration
Finding the LQR controller in closed-form by recursion
The minimum is attained at: \(2Ru + 2B^T P_0 Ax + 2B^T P_0 Bu = \mathbf{0}\)\((R + B^T P_0 B)\mathbf{u} = -B^T P_0 Ax\)
So, the optimal control for the last time step is: \(\mathbf{u} = -(R + B^T P_0 B)^{-1} B^T P_0 Ax\) \(\mathbf{u} = K_1 \mathbf{x}\)
Linear controller in terms of the state
We computed the location of the minimum. Now, plug it back in and compute the minimum value
Finding the LQR controller in closed-form by recursion
\(J_0(x) = x^TQx\)\[\begin{align}
J_1(\mathbf{x}) &= \mathbf{x}^T Q \mathbf{x} + \mathbf{x}^T A^T P_0 A\mathbf{x} + \min_{\mathbf{u}} [\mathbf{u}^T R \mathbf{u} + 2\mathbf{u}^T B^T P_0 A\mathbf{x} + \mathbf{u}^T B^T P_0 B\mathbf{u}] \\
&= \mathbf{x}^T \underbrace{Q + K_1^T R K_1 + (A + B K_1)^T P_0 (A + B K_1)}_{P_1} \mathbf{x}
\end{align}\]
Q: Why is this a big deal?
A: The cost-to-go function remains quadratic after the first recursive step.
Finding the LQR controller in closed-form by recursion
Finite-Horizon LQR: algorithm summary
\(P_0 = Q\)
// n is the # of steps left
Potential problem for states of dimension >> 100:
Matrix inversion is expensive: O(k^2.3) for the best known algorithm and O(k^3) for Gaussian Elimination. \(\swarrow\)
for n = 1…N \(K_n = -(R + B^T P_{n-1} B)^{-1} B^T P_{n-1} A\) \(P_n = Q + K_n^T R K_n + (A + B K_n)^T P_{n-1} (A + B K_n)\)
One pass backward in time:
Matrix gains are precomputed based on the dynamics and the instantaneous cost
Optimal control for time t = N – n is \(\mathbf{u}_t = K_t \mathbf{x}_t\) with cost-to-go \(J_t(\mathbf{x}) = \mathbf{x}^T P_t \mathbf{x}\) where the states are predicted forward in time according to linear dynamics
One pass forward in time:
Predict states, compute controls and cost-to-go
LQR: general form of dynamics and cost functions
Even though we assumed
we can also accommodate
\(\mathbf{x}_{t+1} = A \mathbf{x}_t + B \mathbf{u}_t\)
Then the form of the optimal policy is the same as in LQR \(\mathbf{u}_{t} = K_t \mathbf{x}_t + \mathbf{k}_t\)
No need to change the algorithm, as long as you observe the state at each step (closed-loop policy)
Linear Quadratic Gaussian LQG
LQR summary
Advantages:
If system is linear LQR gives the optimal controller that takes the system’s state to 0 (or the desired target state, same thing)
Drawbacks:
Linear dynamics
How can you include obstacles or constraints in the specification?
Not easy to put bounds on control values
Today’s agenda
• Intro to Control & Reinforcement Learning • Linear Quadratic Regulator (LQR)
• Iterative LQR
• Model Predictive Control
• Learning dynamics and model-based RL
Use LQR Backward Pass on the approximate dynamics \(f(\delta x_t, \delta u_t)\) and cost \(\tilde{c}(\delta x_t, \delta u_t)\)
Do a forward pass to get \(\delta u_t\) and \(\delta x_t\) and update state and action sequence and \(\bar{x}_0, \ldots, \bar{x}_N\) and \(\bar{u}_0, \ldots, \bar{u}_N\)
Iterative LQR: convergence & tricks
• New state and action sequence in iLQR is not guaranteed to be close to the linearization point (so linear approximation might be bad)
• Trick: try to penalize magnitude of \(\delta u_t\) and \(\delta x_t\)
Replace old LQR linearized cost with \((1 - \alpha) \, \tilde{c}(\delta \mathbf{x}_t, \delta \mathbf{u}_t) + \alpha \left( \| \delta \mathbf{x}_t \|^2 + \| \delta \mathbf{u}_t \|^2 \right)\)
• Problem: Can get stuck in local optima, need to initialize well
• Problem: Hessian might not be positive definite
Today’s agenda
• Intro to Control & Reinforcement Learning • Linear Quadratic Regulator (LQR) • Iterative LQR
• Model Predictive Control
• Learning dynamics and model-based RL
Open loop vs. closed loop
• The instances of LQR and iLQR that we saw were open-loop
• Commands are executed in sequence, without feedback
• Idea: what if we throw away all commands except the first
• We can execute the first command, and then replan Takes into account the changing state
Model Predictive Control
while True:
observe the current state \(x_0\)
run LQR/iLQR or LQG/iLQG or other planner to get \({u}_0, \ldots, {u}_{N-1}\)
Execute \(u_0\)
Possible speedups:
Don’t plan too far ahead with LQR
Execute more than one planned action
Warm starts and initialization
Use faster / custom optimizer (e.g. CPLEX, sequential quadratic programming)
Online trajectory optimization / MPC
Online trajectory optimization / MPC
Online trajectory optimization / MPC
Test 3: Dynamic Maneuvers
Online trajectory optimization / MPC
Today’s agenda
• Intro to Control & Reinforcement Learning • Linear Quadratic Regulator (LQR) • Iterative LQR • Model Predictive Control
• Learning dynamics and model-based RL
Learning a dynamics model
Idea #1: Collect dataset \(D = \{(x_t, u_t, x_{t+1})\}\)
do supervised learning to minimize \(\sum_{t} \left\| f_{\theta}(x_t, u_t) - x_{t+1} \right\|^2\)
and then use the learned model for planning
Possibly a better idea: instead of minimizing single-step prediction errors, minimize multi-step errors.
See “Improving Multi-step Prediction of Learned Time Series Models” by Venkatraman, Hebert, Bagnell
Possibly a better idea: instead of predicting next state predict next change in state.
See “PILCO: A Model-Based and Data-Efficient Approach to Policy Search” by Deisenroth, Rasmussen
Plan through \(f_{\theta}(x_t, u_t)\) to get actions
Execute first action, observe new state \(x_{t+1}\)
Append \((x_t, u_t, x_{t+1})\) to \(D\)
Today’s agenda
• Intro to Control & Reinforcement Learning • Linear Quadratic Regulator (LQR) • Iterative LQR • Model Predictive Control • Learning dynamics and model-based RL
• Appendix
Appendix #1 (optional reading) LQR extensions: time-varying systems
• What can we do when \(x_{t+1} = A_t x_t + B_t u_t\) and \(c(x_t, u_t) = x_t^T Q x_t + u_t^T R u_t\) ?
• Turns out, the proof and the algorithm are almost the same
Optimal controller for n-step horizon is \(u_n = K_n x_n\) with cost-to-go \(J_n(x) = x^T P_n x\)
Appendix #2 (optional reading) Why not use PID control?
• We could, but:
• The gains for PID are good for a small region of state-space.
• System reaches a state outside this set → becomes unstable
• PID has no formal guarantees on the size of the set
• We would need to tune PID gains for every control variable.
• If the state vector has multiple dimensions it becomes harder to tune every control variable in isolation. Need to consider interactions and correlations.
• We would need to tune PID gains for different regions of the state-space and guarantee smooth gain transitions
• This is called gain scheduling, and it takes a lot of effort and time
LQR addresses these problems
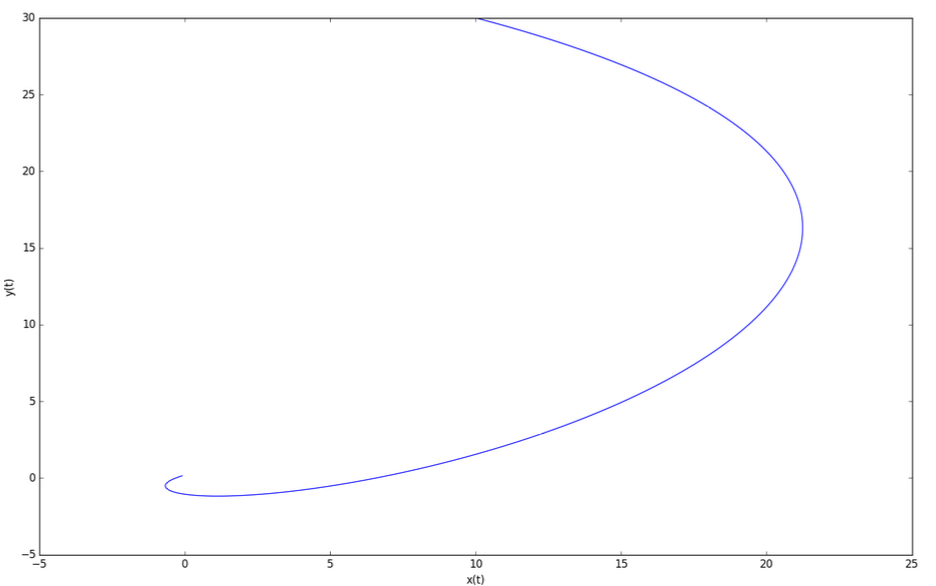
Appendix #3 (optional reading) Examples of models and solutions with LQR
LQR example #1: omnidirectional vehicle with friction
• Similar to double integrator dynamical system, but with friction:
\[
\underset{\color{red}\text{Force applied to the vehicle}}{\underline{m\ddot{p}}} = \underset{\color{red}\text{Control applied to the vehicle}}{\underline{\mathbf{u}}} - \underset{\color{red}\text{Friction opposed to motion}}{\underline{\alpha \dot{p}}}
\]
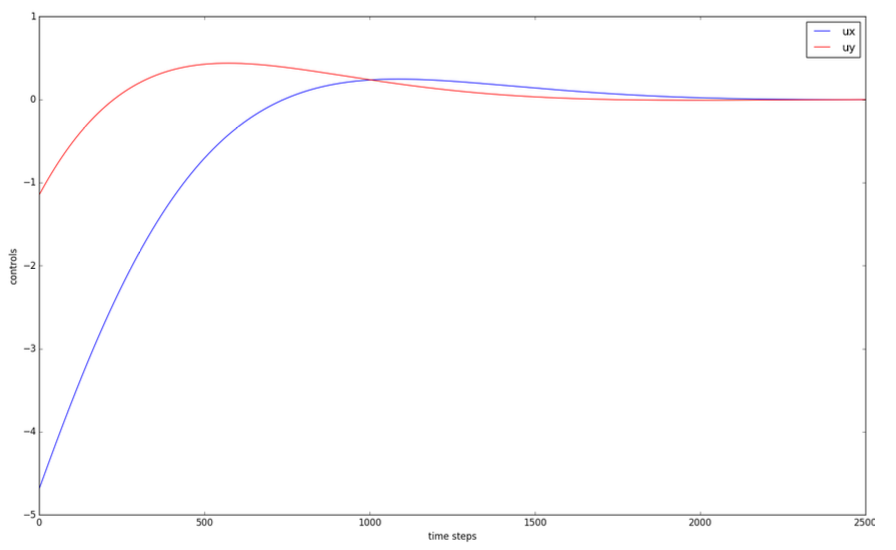
LQR example #1: omnidirectional vehicle with friction
• Similar to double integrator dynamical system, but with friction:
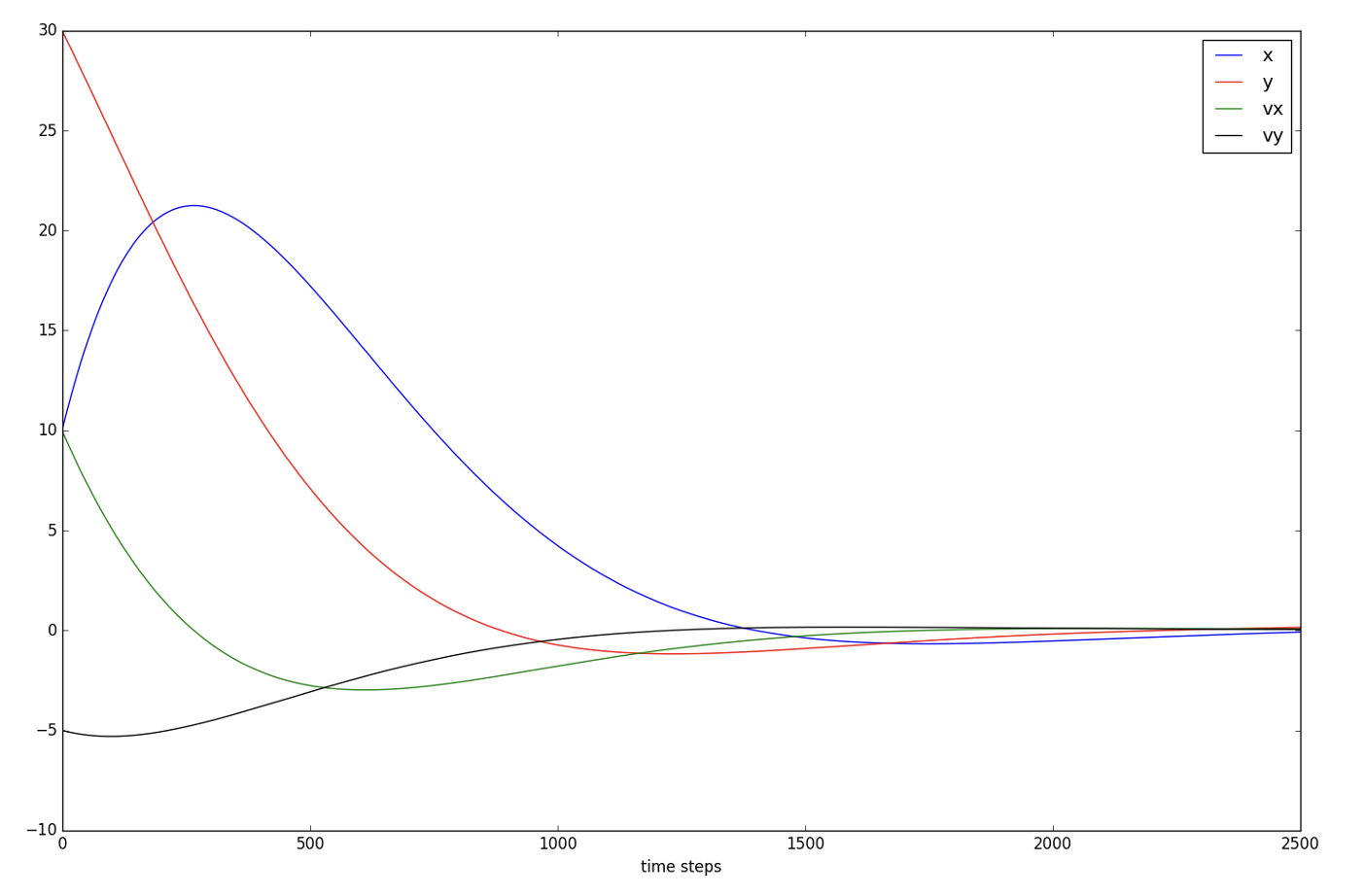
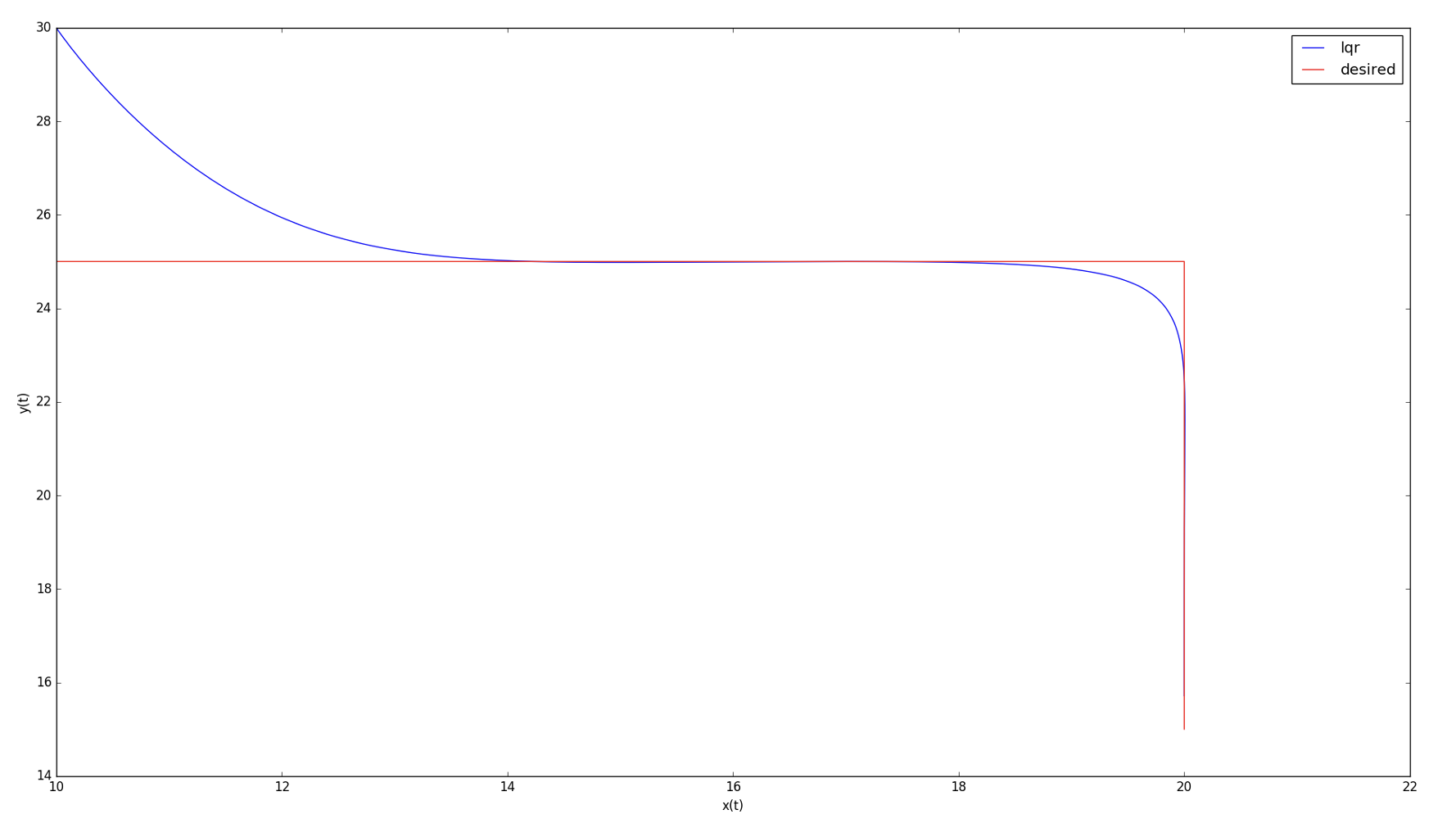
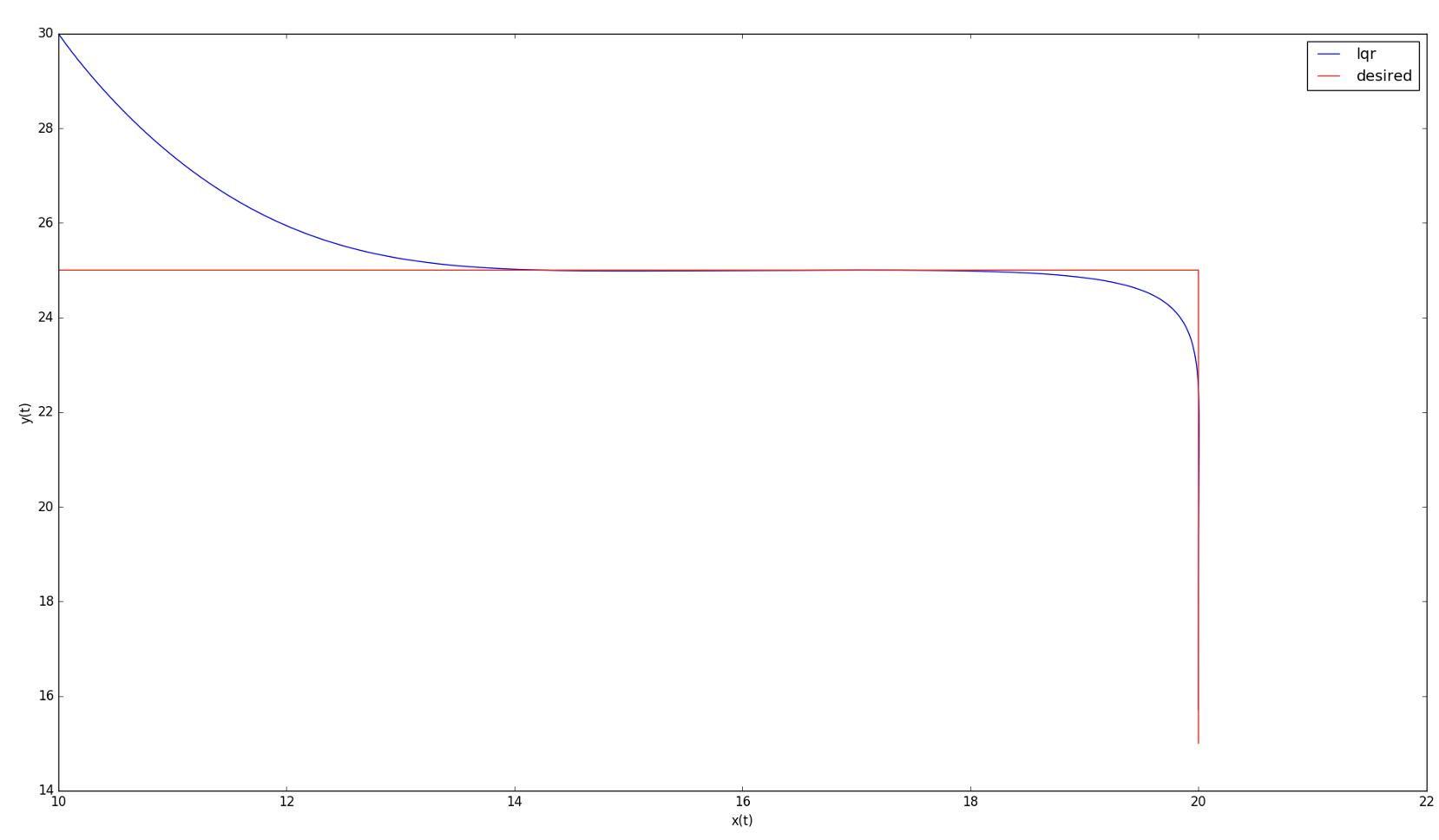
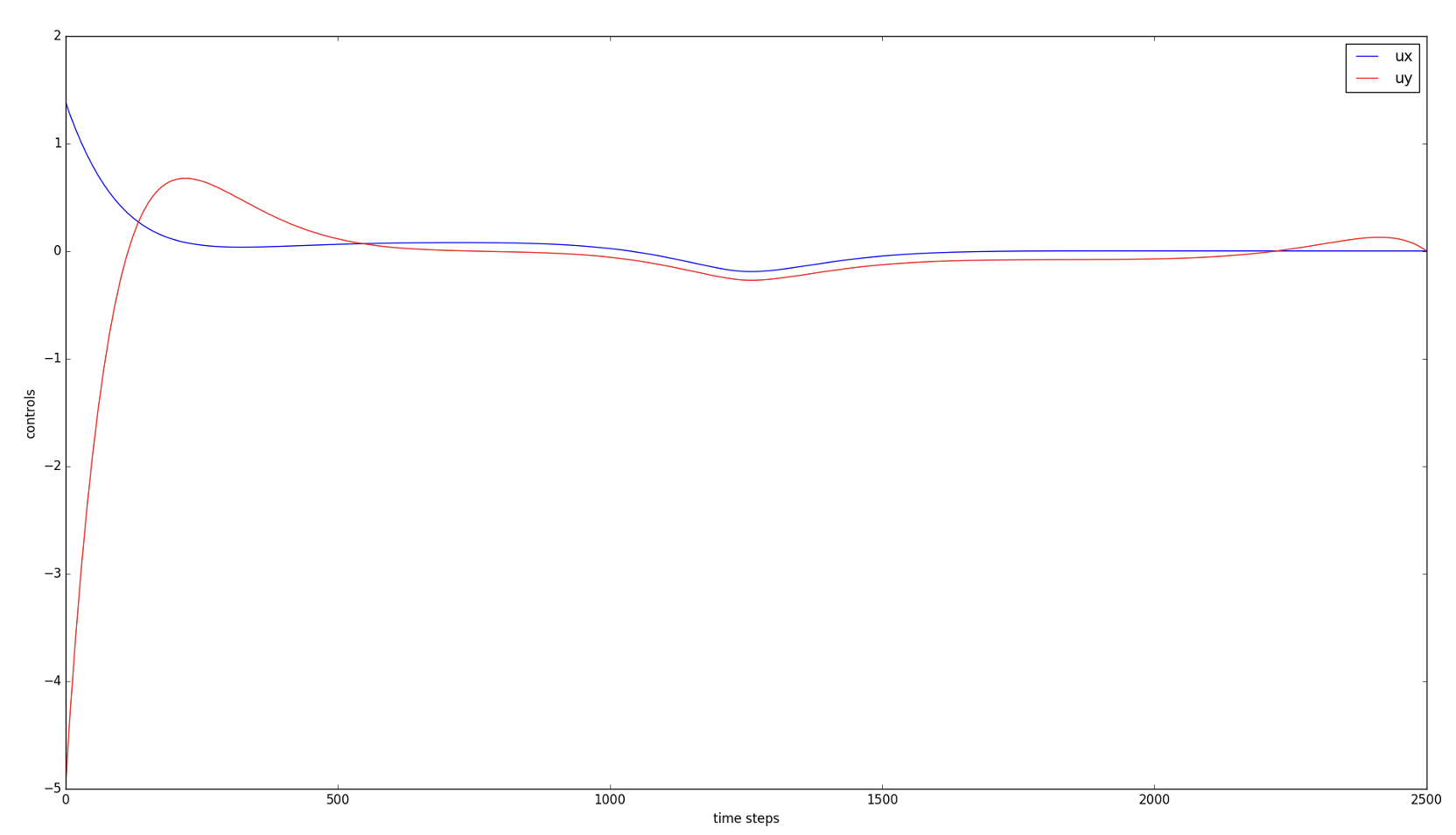
Notice how the controls tend to zero.
It’s because the state tends to zero as well.
Also note that in the current LQR framework,
we have not included hard constraints on the controls,
i.e. upper or lower bounds. We only penalize large norm for controls.
LQR example #1: omnidirectional vehicle with friction
With initial state \(\mathbf{x}_0 = \begin{bmatrix}10 \\ 30\\ 10\\ -5\end{bmatrix}\)